这个文件主要是因为在blog过多之后如果继续使用白嫖的leancoud服务的话就容易报Too Many Request的问题而做的改进,在每次deploy的时候会对数据做一个本地备份,而在ci脚本中,之前完全没有意识到这个问题,从而导致了每次在ci服务器上生成的.memo文件生成完就被丢弃了,可以说完全没有起作用,所以主要也是要解决leancloud.memo的持久化问题.
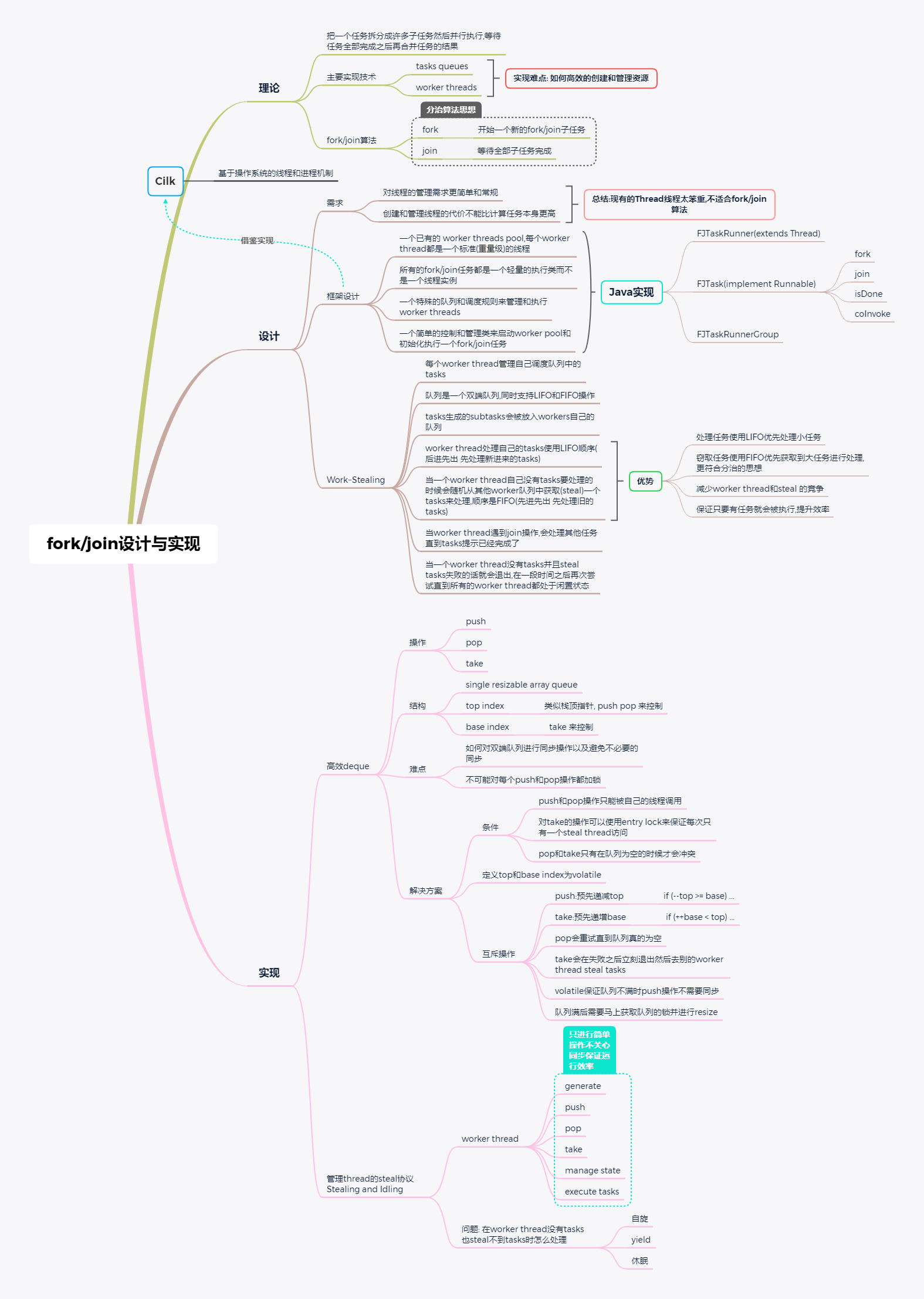
/* This test catches both overflows and index wraps. It doesn't really matter if base value is in the midst of changing in take. As long as deq length is < 2^30, we are guaranteed to catch wrap in time since base can only be incremented at most length times between pushes (or puts). */ // 这里是重点,注释中也已经讲的很清楚了 if (t < (base & (deq.length-1)) + deq.length) {
deq[t & (deq.length-1)].put(r); top = t + 1; }
else// isolate slow case to increase chances push is inlined slowPush(r); // check overflow and retry }
// slowPush主要是为了应对数组的resize /** * Handle slow case for push **/
protectedsynchronizedvoidslowPush(final FJTask r) { checkOverflow(); push(r); // just recurse -- this one is sure to succeed. }
/** * Return a popped task, or null if DEQ is empty. * Called ONLY by current thread. * <p> * This is not usually called directly but is * instead inlined in callers. This version differs from the * cilk algorithm in that pop does not fully back down and * retry in the case of potential conflict with take. It simply * rechecks under synch lock. This gives a preference * for threads to run their own tasks, which seems to * reduce flailing a bit when there are few tasks to run. **/
protectedfinal FJTask pop() { /* Decrement top, to force a contending take to back down. */
intt= --top;
/* To avoid problems with JVMs that do not properly implement read-after-write of a pair of volatiles, we conservatively grab without lock only if the DEQ appears to have at least two elements, thus guaranteeing that both a pop and take will succeed, even if the pre-increment in take is not seen by current thread. Otherwise we recheck under synch. */
/** * Check under synch lock if DEQ is really empty when doing pop. * Return task if not empty, else null. **/
protectedfinalsynchronized FJTask confirmPop(int provisionalTop) { if (base <= provisionalTop) return deq[provisionalTop & (deq.length-1)].take(); else { // was empty /* Reset DEQ indices to zero whenever it is empty. This both avoids unnecessary calls to checkOverflow in push, and helps keep the DEQ from accumulating garbage */
/** * Take a task from the base of the DEQ. * Always called by other threads via scan() **/
protectedfinalsynchronized FJTask take() {
/* Increment base in order to suppress a contending pop */ intb= base++; if (b < top) return confirmTake(b); else { // back out // take的机制就是类似于fail fast, 会去尝试窃取其他线程的taks base = b; returnnull; } }
/** * double-check a potential take **/
protected FJTask confirmTake(int oldBase) {
/* Use a second (guaranteed uncontended) synch to serve as a barrier in case JVM does not properly process read-after-write of 2 volatiles */
synchronized(barrier) { if (oldBase < top) { /* We cannot call deq[oldBase].take here because of possible races when nulling out versus concurrent push operations. Resulting accumulated garbage is swept out periodically in checkOverflow, or more typically, just by keeping indices zero-based when found to be empty in pop, which keeps active region small and constantly overwritten. */ return deq[oldBase & (deq.length-1)].get(); } else { base = oldBase; returnnull; } } }
/** The threads in this group **/ protectedfinal FJTaskRunner[] threads;
/** Group-wide queue for tasks entered via execute() **/ protectedfinalLinkedQueueentryQueue=newLinkedQueue();
/** * Create a FJTaskRunnerGroup with the indicated number * of FJTaskRunner threads. Normally, the best size to use is * the number of CPUs on the system. * <p> * The threads in a FJTaskRunnerGroup are created with their * isDaemon status set, so do not normally need to be * shut down manually upon program termination. **/
/** * Arrange for execution of the given task * by placing it in a work queue. If the argument * is not of type FJTask, it is embedded in a FJTask via * <code>FJTask.Wrap</code>. * @exception InterruptedException if current Thread is * currently interrupted **/