Java8函数式编程笔记
chp2.
lambda表达式的几种形式
1 | // () -> 表示没有参数且Runnable接口只有一个run方法 |
Lambda 表达式的类型依赖于上下文环境,是由编译器推断出来的。
变量引用:
在lambda表达式中可以引用非final变量但该变量在既成事实上必须是final。也就是只能给该变量赋值一次,也就是值引用。
函数接口:
使用只有一个方法的接口来表示某特定方法并反复使用。
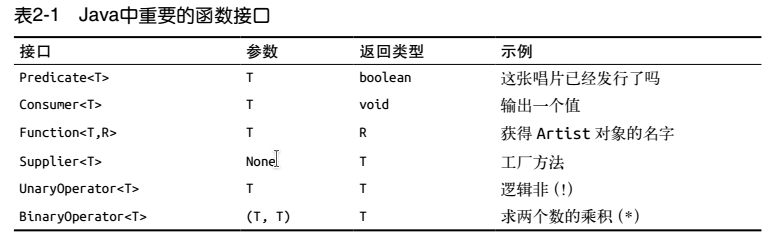
Java中重要的函数接口:
chp3.
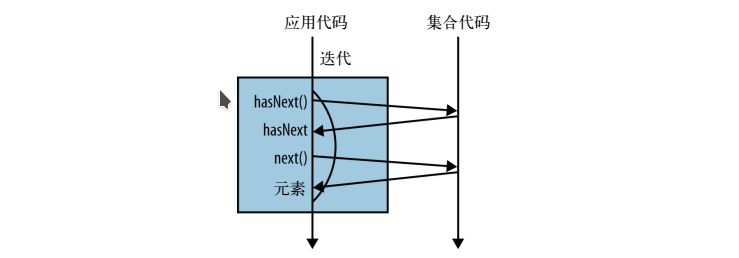
外部迭代
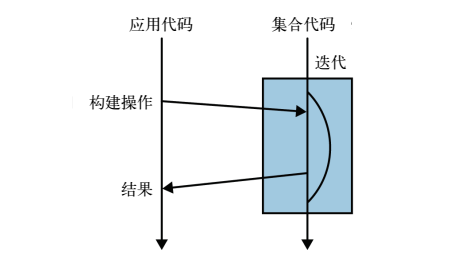
内部迭代
lambda表达式采用惰性求值,在没有进行及早求知(reduce)之前不会进行前面的求值操作。 ex:
1 | // 由于采用惰性求值,这个表达式并不会有输出 |
常用流操作
collect(toList()) : 由Stream里的值生成一个列表,是一个及早求值操作。
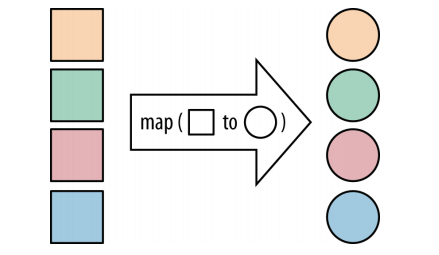
map : 将一个流中的值转换成一个新的流。
filter :
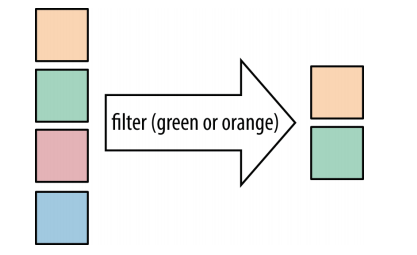
1
2
3
4// ex
List<String> beginningWithNumbers = Stream.of("a", "1abc", "abc1")
.filter(value -> isDigit(value.charAt(0)))
.collect(toList());flatMap : 用Stream替换值,然后将多个Stream连接成一个Stream
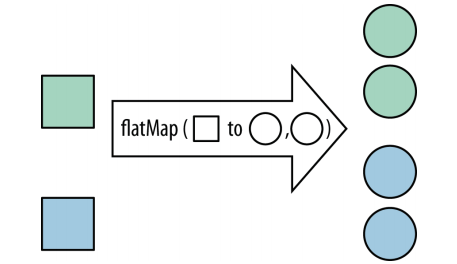
max,min
1
2
3
4// ex:
Track shortestTrack = tracks.stream()
.min(Comparator.comparing(track -> track.getLength()))
.get();reduce
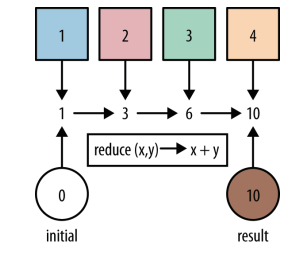
1
2
3
4
5
6
7
8
9
10// 使用reduce求和
int count = Stream.of(1, 2, 3)
.reduce(0, (acc, element) -> acc + element);
// 展开reduce
BinaryOperator<Integer> accumulator = (acc, element) -> acc + element;
int count = accumulator.apply(
accumulator.apply(
accumulator.apply(0, 1),
2),
3);
chp4.
labmda类型推导

默认方法
三定律
如果对默认方法的工作原理, 特别是在多重继承下的行为还没有把握, 如下三条简单的定律可以帮助大家。
- 类胜于接口。 如果在继承链中有方法体或抽象的方法声明, 那么就可以忽略接口中定义的方法。
- 子类胜于父类。 如果一个接口继承了另一个接口, 且两个接口都定义了一个默认方法,
那么子类中定义的方法胜出。 - 没有规则三。 如果上面两条规则不适用, 子类要么需要实现该方法, 要么将该方法声明为抽象方法。
其中第一条规则是为了让代码向后兼容。
Optional
(这里的介绍有点简略)

chp5.
方法引用
1 | // idea会在写出前一种形式的时候给出修改建议 |
元素顺序
- 在一个有序集合中创建一个流时, 流中的元素就按出现顺序排列
- 如果集合本身就是无序的, 由此生成的流也是无序的
收集器
- 使用 toCollection, 用定制的集合收集元素 ->
stream.collect(toCollection(TreeSet::new)); - 生成值
- maxBy ->
artists.collect(maxBy(comparing(getCount))); - averagingInt ->
.collect(averagingInt(album -> album.getTrackList().size()));
- maxBy ->
- 分块(partition)->
return artists.collect(partitioningBy(Artist::isSolo)); - 分组(groupby)
1
2
3
4// 返回Map k,v value为对象的List
public Map<Artist, List<Album>> albumsByArtist(Stream<Album> albums) {
return albums.collect(groupingBy(album -> album.getMainMusician()));
} - 字符串 ->
.collect(Collectors.joining(", ", "[", "]"));joining(分割符,前缀,后缀) - 组合收集器(下游收集器)
1
2
3
4
5
6// counting
albums.collect(groupingBy(album -> album.getMainMusician(),
counting()));
// mapping
return albums.collect(groupingBy(Album::getMainMusician,
mapping(Album::getName, toList())));