Lec10.
Search
- ordered - binary - log n
- unordered - liner - n
Divide & conquer(分治)
- split the problem into several sub-problem of the same type
- solve independently
- combine solutions
MergeSort(归并排序)
- divide list in half.
- continue until we have single lists.
- merge of the sublists
复杂度:n(每一次要操作的数的个数)logn(归并的次数)
适用的场合:要归并的元素不是很复杂而且归并的操作简单
Hashing:
- 牺牲空间来换取时间效率
- hard to create(需要寻找一个好的哈希函数)
Python语法.Exception:
- unhandle
- handle:捕获可以预期的异常并且处理.
Exception vs Assert
- 断言是一种测试,保证断言的语句为真才能继续执行下去
- 异常保证程序在出现预期的出错的时候可以处理它
使用异常的原因:为了保证在异常出现的时候可以正确的捕获和处理它,而不是使得异常向别的地方抛出并且扩散,使得错误无法正确的定位(难以Debug).
Lec11.
Testing && Debugging:
Validation:(验证过程)
- process to uncover problems & inciease confidence
- Testing & Reasoning
Debugging:
- process of ascertaining why program failing
- function(程序是否按照希望的那样完成了操作) & performance(为什么程序运行的效率低)
Defensive programing:(防卫性程序)
- abet validation & debugging
- 使用断言(assert)来尽早发现程序中的问题,给模块添加注释和说明
Testing:
- examine input/output pairs
- Unit testing:单独测试程序中的每个部分:
- integration testing(集成测试):把整个程序组合起来看能否正常运行
在做集成测试之前要对每个单元先做单元测试保证其正确.
Test suite(测试集):
- small enough:保证可以运行完测试集中的数据
- large enough:保证我们对程序有足够的信心
Myth:
- bugs crawl into programs
- bugs breed into programs(bug不会繁殖)
Goal: Not to eliminate one bug, is to move towards a bug-free program:不只是要去消除一个bug,而是要让程序中没有bug出现(消除一个bug做的不好,会带入更多的bug).
最好的debug工具:
- print statement
- reading,阅读代码是最重要的debug技能
- be systematic:形成系统化的调试
- reduce search space(缩减问题的空间来定位问题)
- localize source of problem
如何形成系统化的测试?
- study program text
- how could it have produced this result(阅读代码并且搞清楚程序为什么会产生这个结果)
- is it part of family:是不是在整个系统中重复犯了同一个错误,然后一次性修复一系列相同的问题
- how to fix it?
- scientific method
- study avaliable data:test results(所有的测试结果),program test
- form hypothesis
- design & run repeatable experiment
- refute hypothesis
- useful intermediate results
- expected result(自己对实验的预期结果)
设计一个好的测试:
- find simplest input:找到最简单的输入并且在程序中缩小问题的范围然后定位
- binary search:如果每次能排除掉一半的数据或者代码,定位问题的速度就会很快
Lec12.
调试的一些技巧(习惯):
- 参数的顺序问题
- 拼写
- 初始化变量
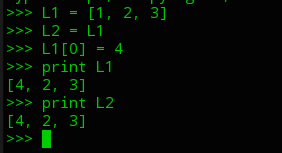
- object vs value equality
- aliasing: deep vs shallow copy
- side-effects:副作用
- Keep record of what you tried:记录你做过的操作
- Reconsider assumption:重新思考你的猜测
- Debug code, not comments
- Get help, explain:向别人获取帮助,并且向别人解释你这段程序的作用
- walk away
- haste makes waste:欲速则不达,在修改之前好好考虑清楚修改引起的变化
- code should not always grow:不能依靠增加代码的方式来修复bug
- make sure that you can revert:确保你可以还原你的代码,如果修改失败,最起码可以回到问题的起点重新开始.
optimization problem:(最优化问题)
- a function to maximize(min):最大化或者最小化一个函数
- a set of constraints(一系列的约束条件)
经典的最优化问题:
- 最短路
- 旅行商问题(TSP)
- bin packing(装箱问题)
- sequence alignment(序列调整)
- Knapsack(背包问题)
- problem reduction(问题约束):把新的问题规约到老的问题上,解决它
continuous knapsack(连续背包):->Greedy algorithm:每一步都选择最优的策略,但是局部最优叠加并不一定导致全局的最优
0/1 knapsack(01背包):
最大化的函数:sum(i=1,n)=Pi*Xi
约束条件:sum(i=1,n)=Wi*Xi <= C
对于暴力来说复杂度是指数级增长,不适用于这个问题
dynamic programming:(动态规划)
- overlapping sub-problems(重叠子问题)
- optimal sub-structure(最优子结构)
从求Fibnacci序列来看什么是重叠子问题:fib(0),fib(1),fib(2)…都被重复计算==>重叠子问题