2023年总结
开始
随着年龄的增长,似乎也到了要写日记的年纪了(正经人谁口口口)。况且今年算是一个特殊的年份,呐,就来回顾一下今年的种种罢。
健康
从健康来回顾是一个不错的开始。今年的生活节奏也有了很大的变化,虽然离年初的目标仍有一段距离,但是也值得记录一下。
起源
经过去年一年在奋斗逼之都的摧残之后,已经意识到了健康生活的重要性。在健康学习到150岁 - 人体系统调优不完全指南和程序员延寿指南 | A programmer’s guide to live longer的契机下,决定好好调整今年的生活作息。
作息
最重要的当然是日常作息了,主要的优化方式就是从12点之后睡觉改为11点入睡,7点起床(当然也和工作时间调整有关)。
喝水
虽然看上去是一个不起眼的优化,但是回过头来看应该是本年度最有性价比的改动了。在下载了喝水app并严格执行每日喝水目标之后确实能感觉到身体的变化。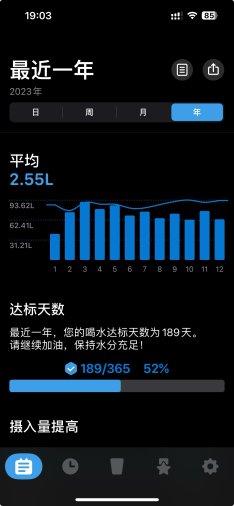
减肥&&锻炼
从奋斗逼之都被赶回来的时候已经接近90kg了,上称的时候确实有点不能接受。所以今年最大的目标就是减肥。然而作为一个没有毅力的人(不然也不会到达这个体重),自然是要选择easy path了。在经过仔细调研之后决定第一步就是先喝水,于是就有了用app强制喝水的故事。一开始确实非常的难受,需要一直跑厕所,但是还好那段时间在家里蹲所以也没有什么大碍。在大概经过1个月之后身体就已经可以适应正常的饮水量了。而喝水的另一个好处,作为民科的我的想法是:饭前喝水可以一定程度稀释胰岛素水平(加上占据胃容量),可以在更少饮食的情况下不那么饥饿。
减肥最重要的当然是饮食了,对此我的策略一开始是:早饭正常吃,中午一个板烧鸡腿堡,晚上一口饭+吃菜。由于前置了一个月的喝水计划,所以在执行到这里的时候并没有非常的折磨,当然晚上也是会饿的,所以也买了一堆牛肉干来尝试,最后的选择是下面这款:
由于提早了睡眠时间,所以晚上饥饿的程度也不会那么严重,总体来说减少摄入在早睡和多喝水的优化下比较轻松就达成了。而目前我的策略是所谓的8+16进食法:早饭不吃一杯牛奶,中午正常吃,晚饭不吃饭光吃菜。
锻炼的部分,一开始只是在家里做简单的深蹲。后面改为了骑车上班(15km)+动感单车的形式,夏秋两季的运动量是最多的。感觉最好的还是省了两个月的油钱,还是在油价的最高点(不是。
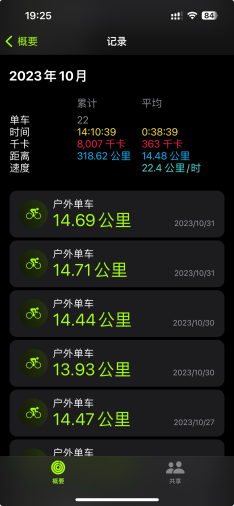
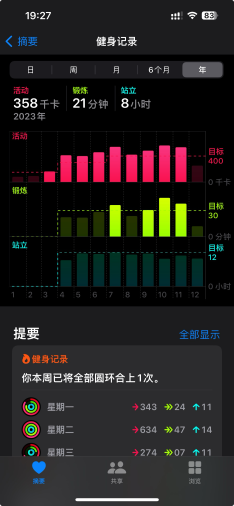
在运动之于最大的收获就是发现了屌丝神器迪卡侬,已经成为忠实用户了。
所以在达成了75kg目标的今天还是非常满意的(虽然年初的目标是70kg)。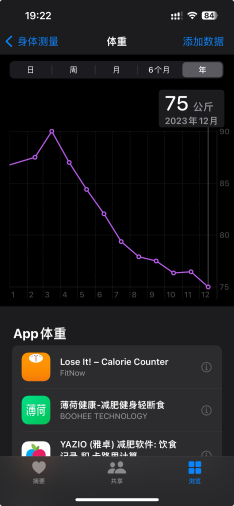
游戏
今年在搬进新家之后买了太差了电视和ps5,终于可以好好的玩游戏了~ 而今年最多的游戏时光也是在ps5上面。但是我还是要说ps5会员你就是个寄吧。纯纯的垃圾(特别是大镖客出会免)
异度之刃3
在过年的时候作为出门做客消遣的游戏算是狠狠的玩了一阵,非常的沉迷非常的好玩,今年过年玩xb2。
个人评价:系统、地图非常不错,吊打国内开放世界手游。但是受限于ns的垃圾机能,人物大部分时间马赛克严重,非常影响游玩。剧本方面主角太多,非常菜市场,没有能够完美塑造全部的角色或者重点塑造一对男女主,少点味。
而且感觉xb2,3的系统都非常适合手游化甚至可以达到好玩的程度,不知道为什么日厂不做。
死亡搁浅
作为ps5会免的第一个体验的游戏,只能说画质非常的不错。但是放下之后就很难再拿起来玩了。
战神5
画质非常炫酷,作为ps5的扛鼎之作,虽然战斗系统方面还是4的那一套做了迭代。但是总体流程玩下来很爽快,不亏。好评。
对马岛之魂
ps5会免游戏,在多年不吃育碧罐头之后再来品味甚至别有一番风味。战斗之后的振刀收刀非常的帅气,很有剑戟片的感觉。风景也很不错。好评。
FF16
年度答辩之作,对rpg的最大侮辱,吉田还是滚回去做ff14吧。
美末1
在另一篇文章中已经品鉴过了,好评。
荒野大镖客
好玩,但是后期有点没耐心了。而且剧本走向悲剧,在不那么快乐的2023年玩起来有点压抑。
十三机兵防卫圈
自己买了盘刚要玩就进入会免。。二刷,希望哪天又失忆了可以再玩一遍。 好好评。
王国之泪
对旷野之息的迭代,感觉其实王泪才是老任一开始想要做到的样子。好玩,但是机能太垃圾了,玩到一半搁置。等ns2再玩。
阅读
Crafting Interpreters
写编译器和解释器的书,从0开始。非常适合新手,而且有免费的HTML版本,搭配双语翻译效果绝佳。今年最值得推荐的书。
可能性的艺术 比较政治学
适合作为政治学入门书籍观看,还不错(看的原因是据说被ban了,逆反)。
计算 吴瀚清
新书,第一部分感觉可以和《什么是数学》《数学 它的内容方法和意义》一起观看,属于数学简史类型的科普。
刘擎西方现代思想讲义
科普哲学思想的书,图一乐之外也能大致了解各个思想学派和发展路径。
工作、消费主义和新穷人
没什么印象,简单来说工作只是资本主义对人的一种规训,不努力工作,薅资本家羊毛才是正途。
置身之内
知道了地方和中央也不是铁板一块,地方只会在拿着上面的要求一顿排列组合之后选择电阻最低的路径(easy path)来实现上面的KPI和自己的目标。
天朝的崩溃
在绝对的科技优势面前任何的努力或者忠诚都是无用的,无论你是文官还是将军,在看到英军战斗的那一刻就能知道,时代已经变了而你无能为力。你能做的只有一路瞒到国务院或者议和止损保住自己的狗命。
购物
石头G10S
搬了新家之后购入了扫地机器人,总体来说非常不错,很省心。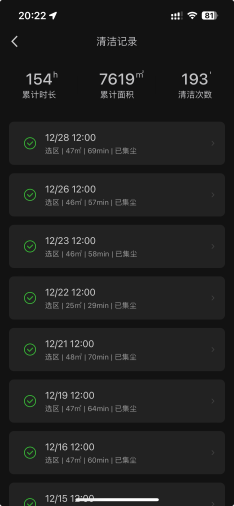
PS5
值得,就是夏天过热自动关机有点绷不住。
群晖+Apple TV
看蓝光原盘的电影很爽。
Apple Watch SE
为了记录运动买的,总体不错,就是一天一充还是有点接受不了。
升降桌
买了电机和桌面自己组装的,现在已经习惯了站立工作。
工作
今年最值得说的可能就是工作吧,但是现在的我来说,觉得还是要将其放到更低的位置(生活更重要)。
虽然一想起来可能有很多话要讲,但是最后写出来的可能也就那样:
从去年10月被奋斗逼公司卸磨杀驴之后在杭州并找不到工作,然后灰溜溜回家过年。年前机缘巧合面了现在这家老家的公司,干到现在也快一年了。虽然薪资对半砍了,但是获得了8:30上班,5:30下班的清闲日子,也才有了健康生活还能锻炼的一年。
作为一个三年三家公司,四年四家的loser,今年也来到了工作的第四个年头。个人感觉自己还是挺幸运的,赶上了互联网的末班车蹭到了几年经验,现在也还没有失业在家。也有时间做自己喜欢的事。