14.6.3 表空间(Tablespaces) 14.6.3.1 系统表空间(The System Tablespace) InnoDB系统表空间包含了InnoDB数据文件(InnoDB相关的对象元数据)并且存储区域是双写缓存,变更缓存和undo日志的存储区域.系统表空间也包含了用户创建在系统表空间中的表和索引数据.
系统表空间有一到多个数据文件.默认情况下名为 ibdata1的系统表空间数据文件被创建在数据目录下.系统表空间的大小和数量由innodb_data_file_path启动选项控制.
调整系统表空间(Resizing the System Tablespace)
增加InnoDB系统表空间的大小
增加InnoDB系统表空间大小的最简单方法是从一开始就将其配置为自动扩展.在表空间定义中指定最后一个数据文件为autoextend属性.然后InnoDB在空间不足时以64MB为增量自动增加该文件的大小.可以通过设置innodb_autoextend_increment系统变量的值来更改增量大小,以MB为单位.
你可以添加另一个数据文件指定数量来扩展系统表空间:
关闭MySQL服务器.
如果之前的最后一个数据文件定义了关键字 autoextend,根据基于实际增长的大小改变其定义为固定的大小.检查数据文件的大小,将其向下舍入为最接近的1024×1024字节的倍数(1MB),然后在 innodb_data_file_path指定这个大小.
在 innodb_data_file_path配置后添加一个新的数据文件,配置其自动扩展.只有 innodb_data_file_path中的最后一个文件可以被指定为自动扩展.
启动MySQL服务器.
例如,表空间只有一个自动扩展的数据文件ibdata1:
1 2 innodb_data_home_dir = innodb_data_file_path = /ibdata/ibdata1:10M:autoextend
假如这个数据文件在一段时间之后增长到了988MB.以下是修改原始数据文件使用固定大小并添加新的自动扩展数据文件后的配置:
1 2 innodb_data_home_dir = innodb_data_file_path = /ibdata/ibdata1:988M;/disk2/ibdata2:50M:autoextend
当你在系统表空间配置中添加一个新的数据文件的时候,确保文件路径不会引用到已存在的文件.InooDB会在你重启服务器的时候创建这个文件.
减小InnoDB系统表空间的大小
你不能删除系统表空间的数据文件.要减小系统表空间,使用下面的步骤:
使用mysqldump备份你所有的InnoDB表,包括位于MySQL数据库中的InnoDB表.从5.6开始,MySQL数据库中包含五个InnoDB表: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 mysql> SELECT TABLE_NAME from INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA= 'mysql' and ENGINE= 'InnoDB' ; + | TABLE_NAME | + | engine_cost | | gtid_executed | | help_category | | help_keyword | | help_relation | | help_topic | | innodb_index_stats | | innodb_table_stats | | plugin | | server_cost | | servers | | slave_master_info | | slave_relay_log_info | | slave_worker_info | | time_zone | | time_zone_leap_second | | time_zone_name | | time_zone_transition | | time_zone_transition_type | +
关闭服务器
删除所有存在的表空间文件(*.ibd),包括 ibdata和 ib_log文件.不要忘记删除MySQL数据库中表的*.ibd文件.
删除全部InnoDB表的.frm文件.
配置一个新的表空间.
重启服务器.
导入备份文件
为系统表空间使用原始磁盘分区(Using Raw Disk Partitions for the System Tablespace)
你可以在InnoDB系统表空间中使用原始磁盘分区作为数据文件.此技术可在Windows和某些Linux和Unix系统上启用非缓冲I/O,而无需文件系统开销.使用和不使用原始分区执行测试以验证此更改是否实际上提高了系统性能.
使用原始磁盘分区时,请确保运行MySQL服务器的用户具有该分区的读写权限.例如,如果你使用mysql用户运行服务,mysql用户就必须有这个分区的读写权限.如果你使用 –memlock配置运行服务器,服务就必须使用root运行,root就必须有这个分区的读取权限.
下面描述的过程涉及选项文件修改
在Linux和Unix系统上分配原始磁盘分区
创建新数据文件时,在innodb_data_file_path选项的数据文件大小之后立即指定关键字newraw.分区必须至少与指定的大小一样大.请注意,InnoDB中的1MB是1024×1024字节,而磁盘规格中的1MB通常意味着1,000,000字节. 1 2 3 [mysqld] innodb_data_home_dir= innodb_data_file_path=/dev/hdd1:3Gnewraw;/dev/hdd2:2Gnewraw
重启服务器.InnoDB注意到newraw关键字会初始化新分区.但是不要创建或更改任何InnoDB表.否则,当您下次重新启动服务器时,InnoDB将重新初始化分区,并且你的更改将丢失.
在InnoDB初始化新分区后,停止服务器,将数据文件规范中的newraw更改为raw: 1 2 3 [mysqld] innodb_data_home_dir= innodb_data_file_path=/dev/hdd1:3Graw;/dev/hdd2:2Graw
重启服务器后InnoDB就允许进行更改.
在Windows上分配原始磁盘分区
在Windows系统上,除了用于Windows的innodb_data_file_path设置略有不同外,和Linux和Unix系统使用相同步骤和附带指南.
创建新数据文件时,请在innodb_data_file_path选项的数据文件大小之后立即指定关键字newraw 1 2 3 [mysqld] innodb_data_home_dir= innodb_data_file_path=//./D::10Gnewraw
重启服务器.InnoDB注意到newraw关键字并初始化新分区.
在InnoDB初始化新分区后,停止服务器,将数据文件规范中的newraw更改为raw 1 2 3 [mysqld] innodb_data_home_dir= innodb_data_file_path=//./D::10Graw
重启服务器后InnoDB就允许进行更改.
14.6.3.2 单表单文件表空间(File-Per-Table Tablespaces) 在以前,InnoDB表存储在系统表空间中.这种存储方法只适用于专门用于数据库处理的机器,需要仔细计划数据增长,分配给MySQL的任何磁盘存储器永远不会用于其他目的.单表单文件特性提供了一个更加灵活的选择,每个InnoDB表都存储在其自己的表空间数据文件(.ibd)里.这个特性由 innodb_file_per_table配置选项控制,默认开启.
优势
你可以在截断或删除存储在单表单文件表空间中的表时回收磁盘空间.截断或删除存储在系统表空间中的表会在系统表空间内部创建空闲空间,只能被新的InnoDB数据使用.
同样的,驻留在通用表空间中表的表复制ALTER TABLE操作可以增加表空间可以使用的空间总量.此类操作可能需要与表中的数据和索引一样多的额外空间.表复制ALTER TABLE操作所需的额外空间不会像文件每表表空间一样释放回操作系统.
截断表(TRUNCATE TABLE)操作在单表单文件表空间的表上运行更快.
你可以将特定表存储在单独的存储设备上,以进行I/O优化,空间管理或备份.在以前的版本中,你必须将整个数据库目录移动到其他驱动器并在MySQL数据目录中创建符号链接.在MySQL 5.6.6及更高版本中,您可以使用 CREATE TABLE ... DATA DIRECTORY = absolute_path_to_directory指定每个表的位置.
你可以使用OPTIMIZE TABLE来压缩或重建单表单文件表空间.当你运行OPTIMIZE TABLE时,InnoDB创建一个临时文件名的.ibd文件,只使用存储数据实际需要的空间.当优化完成后,InnoDB会删除旧的.ibd文件然后用新的替换.如果之前的.ibd文件显著增长但实际数据只用了很小一部分,执行OPTIMIZE TABLE来回收没有用到的空间.
你可以移除单个的InnoDB表而不是整个数据库.
你可以从一个数据库实例拷贝单个InnoDB表到另一个实例.
创建在单表单文件表空间中的表使用 Barracuda文件格式. Barracuda文件格式支持例如压缩和动态行格式的特性.
你可以使用动态行格式( dynamic row format)来更高效的存储大的BLOB和TEXT列.
单表单文件表空间也提高了成功恢复的机会和节约了崩溃发生时的时间,例如服务器不能重启或备份和二进制日志不可用.
你可以使用MySQL企业备份更快的备份或转存单个表而不会中断其他InnoDB表的使用.如果你的表不需要经常备份或需要使用不同的备份计划,这会是非常有用的.
在复制或备份表时,单表单文件表空间报告每个表的状态会更便利.
你可以在不访问MySQL的情况下监视文件系统级别的表大小.
当 innodb_flush_method设置为 O_DIRECT时,常见的Linux文件系统不允许对单个文件的并发写.因此,将单表单文件表空间和 innodb_flush_method组合时可能会有性能提升.
系统表空间存储了数据字典和重做日志(undo logs),并且InnoDB表空间大小限制也有限制.使用单表单文件表空间,每个表都有其自己的表空间,为增长提供了空间.
潜在缺点
在单表单文件表空间里,每个表都会有没有使用的空间而且这些空间只能被同一张表的行使用.如果没有正确管理的话会导致空间浪费.
fsync 操作必须运行在每个表上而不是单文件.由于每个文件都有单独的fsync操作,因此无法将多个表上的写操作组合到单个I/O操作中.这可能需要InnoDB执行更高的fsync操作总数.
mysqld必须为每个表保留一个打开的文件句柄,如果在每个表的文件表空间中有许多表,这可能会影响性能.
使用更多文件描述符.
MySQL 5.6及更高版本默认开启innodb_file_per_table.如果你要向早期版本兼容,考虑禁用.禁用innodb_file_per_table可防止表复制ALTER TABLE操作将隐藏在系统表空间中的表隐式移动到每个表的文件表空间.
例如,当重组聚簇索引时,使用innodb_file_per_table的当前设置重新创建表.此行为不适用于使用INPLACE算法的ALTER TABLE操作.此行为也不适用于使用CREATE TABLE ... TABLESPACE或ALTER TABLE ... TABLESPACE语法添加到系统表空间的表.这些表不受innodb_file_per_table设置的影响.
如果许多表在增长,则可能存在更多碎片,这可能会阻碍DROP TABLE和表扫描性能.但是,在管理碎片时,在自己的表空间中放置文件可以提高性能.
删除每个表的文件表空间时会扫描缓冲池,对于大小为几十千兆字节的缓冲池,可能需要几秒钟.使用粒度大的内部锁执行扫描,这可能会延迟其他操作.系统表空间中的表不受影响.
innodb_autoextend_increment定义了增量大小(以MB为单位),用于自动扩展变满的通用表空间文件,但不适用于单表单文件表空间文件,无论innodb_autoextend_increment如何,这些文件都是自动扩展的.初始扩展是少量的,之后扩展以4MB增加.
启用单表单文件表空间(Enabling File-Per-Table Tablespaces)
innodb_file_per_table选项默认是开启的.
为了启动innodb_file_per_table,使用 –innodb-file-per-table参数来启动服务或在my.cnf配置文件的[mysqld]部分增加:
1 2 [mysqld] innodb_file_per_table=1
你也可以在服务运行时动态设置 innodb_file_per_table:
1 mysql> SET GLOBAL innodb_file_per_table= 1 ;
启用innodb_file_per_table后,可以将InnoDB表存储在tbl_name.ibd 文件中.与MyISAM存储引擎将索引和数据分别存储在tbl_name.MYD 和tbl_name.MYI 文件中不同,InnoDB将数据和索引存储在一个.ibd文件中.
如果你在启动选择中禁用 innodb_file_per_table或使用SET GLOBAL命令禁用, InnoDB在系统表空间内创建新表,除非使用CREATE TABLE ... TABLESPACE选项将表显式放置在单表单文件表空间或通用表空间中.
无论每个表的文件设置如何,你始终可以读写任何InnoDB表.
要将表从系统表空间移动到其自己的表空间,更改innodb_file_per_table设置并重建表
1 2 mysql> SET GLOBAL innodb_file_per_table= 1 ; mysql> ALTER TABLE table_name ENGINE= InnoDB;
使用CREATE TABLE ... TABLESPACE或ALTER TABLE ... TABLESPACE语法将表添加到系统表空间而不受innodb_file_per_table的影响.要将这些表从系统表空间移动到单表单文件表空间,必须使用ALTER TABLE ... TABLESPACE语法.
14.6.3.3 通用表空间(General Tablespaces) 通用表空间是使用 CREATE TABLESPACE语法创建的共享的InnoDB表空间.通用表空间的功能和特性由下面的几个主题描述:
通用表空间功能(General Tablespace Capabilities)
通用表空间提供以下功能:
和系统表空间一样,通用表空间属于共享表空间也可以存储多表数据.
和单表单文件表空间相比通用表空间有潜在的内存性能优势.在表空间的生命周期内服务器把表空间的元数据放在内存中.在表数量相同的情况下,在通用表空间中的多个表比在单表单文件中消耗更少的内存.
通用表空间的文件可以放在MySQL数据文件夹内部或外部,提供了和对单表单文件表空间一样的存储管理功能和更多的数据文件.和单表单文件表空间一样,把数据文件放到MySQL数据文件外面使你可以管理关键表的性能,为特定表设置RAID或DRBD或把特定表绑定到特定的磁盘上等等.
通用表空间支持Antelope 和Barracuda 文件格式,因此支持所有表的行格式和相关特性.因为支持两种文件格式,通用表空间不依赖innodb_file_format或 innodb_file_per_table设置,这两个变量不会影响任何一个通用表空间.
可以在 CREATE TABLE语句中添加TABLESPACE 选项在通用表空间,单表单文件表空间或系统表空间中创建表.
可以在ALTER TABLE语句中添加TABLESPACE 选项在通用表空间,单表单文件表空间或系统表空间之间移动表.以前,无法将单表单文件表空间中的表移到系统表空间中.有了通用表空间特性,你现在可以这么做了.
创建一个通用表空间(Creating a General Tablespace)
使用 CREATE TABLESPACE语句创建通用表空间1 2 3 4 CREATE TABLESPACE tablespace_name ADD DATAFILE 'file_name' [FILE_BLOCK_SIZE = value ] [ENGINE [= ] engine_name]
当在MySQL数据文件之外创建通用表空间的时候会在MySQL数据目录之内创建一个.isl文件.
例如:
在数据目录内创建一个通用表空间:1 mysql> CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' Engine= InnoDB;
1 mysql> CREATE TABLESPACE `ts1` ADD DATAFILE '/my/tablespace/directory/ts1.ibd' Engine= InnoDB;
只要表空间目录不在数据目录下,就可以指定相对路径.例如 my_tablespace目录和数据目录同级:
1 mysql> CREATE TABLESPACE `ts1` ADD DATAFILE '../my_tablespace/ts1.ibd' Engine= InnoDB;
向通用表空间添加表(Adding Tables to a General Tablespace)
在创建了一个InnoDB通用表空间之后,你可以使用CREATE TABLE tbl_name ... TABLESPACE [=] tablespace_name或 ALTER TABLE tbl_name TABLESPACE [=] tablespace_name向表空间中添加表,如下:
CREATE TABLE:
1 mysql> CREATE TABLE t1 (c1 INT PRIMARY KEY ) TABLESPACE ts1;
ALTER TABLE:
1 mysql> ALTER TABLE t2 TABLESPACE ts1;
通用表空间支持的行格式
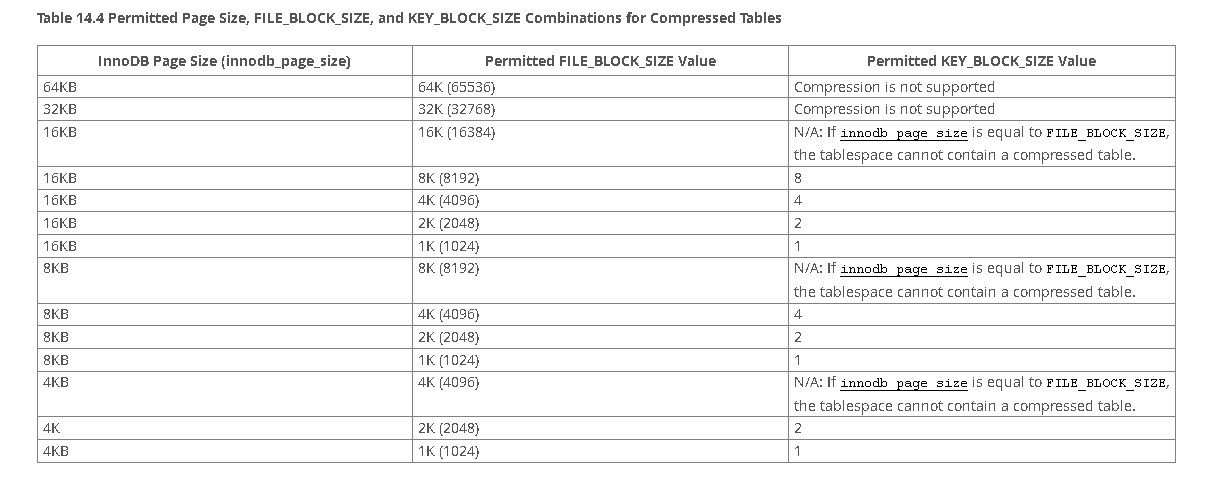
通用表空间支持所有行格式(REDUNDANT, COMPACT, DYNAMIC, COMPRESSED)需要注意的是,由于物理页面大小不同,压缩和未压缩的表不能在同一个通用表空间中共存.
对于包含压缩表(ROW_FORMAT=COMPRESSED)的通用表空间必须指定 FILE_BLOCK_SIZE,并且 FILE_BLOCK_SIZE必须是和 innodb_page_size值相关的有效值.此外,压缩表的物理页面大小(KEY_BLOCK_SIZE)必须等于FILE_BLOCK_SIZE/1024.例如,如果 innodb_page_size=16KB且FILE_BLOCK_SIZE=8K, KEY_BLOCK_SIZE的值就必须是8.
下面的表展示了允许的 innodb_page_size, FILE_BLOCK_SIZE,和KEY_BLOCK_SIZE的组合. FILE_BLOCK_SIZE值也可以指定以字节为单位.为了对于给定FILE_BLOCK_SIZE的值决定合法的 KEY_BLOCK_SIZE值,需要把 FILE_BLOCK_SIZE 除以1024.表压缩不支持32k和64K的InnoDB页大小.
下面的示例演示了如何创建通用表空间并添加压缩表.例子假设 innodb_page_size为16KB.FILE_BLOCK_SIZE 的值为8192要求压缩表的KEY_BLOCK_SIZE 的值为8.1 2 3 mysql> CREATE TABLESPACE `ts2` ADD DATAFILE 'ts2.ibd' FILE_BLOCK_SIZE = 8192 Engine= InnoDB; mysql> CREATE TABLE t4 (c1 INT PRIMARY KEY ) TABLESPACE ts2 ROW_FORMAT= COMPRESSED KEY_BLOCK_SIZE= 8 ;
innodb_page_size.当FILE_BLOCK_SIZE等于 innodb_page_size时,表空间可能只包含没有压缩的行格式的表(COMPACT, REDUNDANT,和 DYNAMIC行格式).
使用ALTER TABLE在两个表空间之间移动表
你可以使用 ALTER TABLE语句加 TABLESPACE 选项移动一个表到一个已存在的通用表空间,一个新的单表单文件表空间或到系统表空间中.
把单表单文件表空间或系统表空间中的表移动到通用表空间中时要指定通用表空间名,指定的通用表空间名要存在.
1 ALTER TABLE tbl_name TABLESPACE [= ] tablespace_name;
把通用表空间或单表单文件表空间中的表移动到系统表空间中时,要指定 innodb_system 为表空间名.
1 ALTER TABLE tbl_name TABLESPACE [= ] innodb_system;
把系统表空间或通用表空间中的表移动到单表单文件表空间中时,要指定 innodb_file_per_table为表空间名.
1 ALTER TABLE tbl_name TABLESPACE [= ] innodb_file_per_table;
ALTER TABLE ... TABLESPACE操作总是会导致完整的表重建,即使TABLESPACE属性没有更改.
ALTER TABLE ... TABLESPACE语法不支持将表从临时表空间移动到持久表空间.
CREATE TABLE ... TABLESPACE = innodb_file_per_table允许DATA DIRECTORY子,,但不支持与TABLESPACE选项结合使用.
删除通用表空间
DROP TABLESPACE语句用于删除InnoDB通用表空间.
必须在DROP TABLESPACE操作之前从表空间中删除所有表. 如果表空间不为空,则DROP TABLESPACE返回错误.
使用类似于以下内容的查询来标识通用表空间中的表:
1 2 3 4 5 6 7 8 9 mysql> SELECT a.NAME AS space_name, b.NAME AS table_name FROM INFORMATION_SCHEMA.INNODB_TABLESPACES a, INFORMATION_SCHEMA.INNODB_TABLES b WHERE a.SPACE= b.SPACE AND a.NAME LIKE 'ts1' ; + | space_name | table_name | + | ts1 | test/ t1 | | ts1 | test/ t2 | | ts1 | test/ t3 | +
如果空的通用表空间上的DROP TABLESPACE操作出错,则表空间可能包含由服务器出口中断的ALTER TABLE操作留下的临时表或中间表.
删除表空间中的最后一个表时,不会自动删除InnoDB的通用表空间.必须使用DROP TABLESPACE tablespace_name显式删除表空间.
通用表空间不属于任何数据库.DROP DATABASE操作可以删除属于通用表空间的表但不能删除表空间,即使DROP DATABASE操作删除属于表空间的所有表也一样.必须使用DROP TABLESPACE tablespace_name显式删除通用表空间.
此示例演示如何删除InnoDB通用表空间.通用表空间中只有t1一张表.必须在删除表空间之前删除表.
1 2 3 4 5 6 7 mysql> CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' Engine= InnoDB; mysql> CREATE TABLE t1 (c1 INT PRIMARY KEY ) TABLESPACE ts10 Engine= InnoDB; mysql> DROP TABLE t1; mysql> DROP TABLESPACE ts1;
通用表空间的限制
生成的或现有的表空间不能更改为通用表空间.
不支持创建临时通用表空间.
通用表空间不支持临时表.
存储在通用表空间中的表只能在支持通用表空间的MySQL版本中打开.
与系统表空间类似,截断或删除存储在通用表空间中的表会在通用表空间.ibd数据文件内部创建可用空间,该数据文件只能用于新的InnoDB数据.空间不会像单表单文件表空间一样释放回操作系统.
此外,共享表空间(通用表空间或系统表空间)中的表上的表复制ALTER TABLE操作可以增加表空间使用的空间量.此类操作需要与表中的数据和索引一样多的额外空间.表复制ALTER TABLE操作所需的额外空间不会像单表单文件表空间一样释放回操作系统.
属于通用表空间中的表不支持LTER TABLE ... DISCARD TABLESPACE和 ALTER TABLE ...IMPORT TABLESPACE.
在MySQL 5.7.24中不支持在通用表空间中放置表分区,在以后的MySQL版本中将删除.
14.6.3.4 Undo表空间 Undo表空间包含了undo日志,undo日志集合包含了如何撤销由事务引起到聚簇索引的最近的修改.undo日志包含在undo日志段中,这些日志段在回滚段中. innodb_rollback_segments变量定义了分配给每个undo表空间的回滚段数.
undo日志可以存储在多个undo表空间中,而不是系统表空间里.此布局与undo日志驻留在系统表空间中的默认配置不同.undo日志的I/O模式使得undo表空间很适合SSD存储,而同时可以把系统表空间存储在硬盘上.
InnoDB的undo表空间的数量由 innodb_undo_tablespaces变量控制.这个配置只能在MySQL实例启动的时候配置,之后不能更改.
undo表空间及这些表空间内相关的段不能被删除.然后undo表空间中的undo日志可以被截断.
配置undo表空间
为了配置MySQL实例的undo表空间,使用下面的步骤.在将配置部署到生产系统之前在测试实例上执行该过程.在部署到生产环境之前在测试环境测试.
使用 innodb_undo_directory配置选项指定undo表空间目录.如果没有指定目录,undo表空间会创建在数据目录内.
使用 innodb_rollback_segments定义回滚段的数量.从一个相对比较低的数值开始,然后逐渐增加数值来查看对性能的影响. innodb_rollback_segments的默认值是128,也可能就是最大值了.
一个回滚段总是分配给系统表空间并且32个回滚段保留给临时表空间(ibtmp1).因此,为了给undo表空间分配回滚段, innodb_rollback_segments的值要比33大.例如,如果你有2个undo表空间,设置innodb_rollback_segments为35可以给每个undo表空间分配一个回滚段.回滚段以循环方式分布在undo表空间中.
当你配置单独的undo表空间时,系统表空间中的回滚段会变为非活动状态.
使用 innodb_undo_tablespaces选项来定义使用undo表空间的数量.指定的undo表空间的数量会在MySQL生命周期内持续生效,所以如果你不知道最佳值,尽量调高数值.
创建一个新的MySQL测试实例来调试这些选项.
在测试服务器上使用和生产服务器上近似的工作负载来进行测试.
对I/O密集型的工作负载进行性能基准测试.
逐步增加innodb_rollback_segments的值并运行性能测试,直到I/O性能没有进一步提高
截断undo表空间(Truncating Undo Tablespaces)
截断undo表空间需要MySQL实例至少有两个活动的undo表空间,用于确保一个undo表空间保持活跃在另一个表脱机进行截断的时候.undo表空间的数量由 innodb_undo_tablespaces定义.默认值是0.使用下面的语句来检测 innodb_undo_tablespaces的值:
1 2 3 4 5 6 mysql> SELECT @@innodb_undo_tablespaces ; + | @@innodb_undo_tablespaces | + | 2 | +
截断undo表空间要先启用 innodb_undo_log_truncate选项,例如:
1 mysql> SET GLOBAL innodb_undo_log_truncate= ON ;
启用innodb_undo_log_truncate变量时,超出innodb_max_undo_log_size大小限制的undo表空间将被截断. innodb_max_undo_log_size是动态的,默认为1024MB.
1 2 3 4 5 6 mysql> SELECT @@innodb_max_undo_log_size ; + | @@innodb_max_undo_log_size | + | 1073741824 | +
当 innodb_undo_log_truncate变量启用的时候:
超过 innodb_max_undo_log_size设置大小的undo表空间被标记为截断.对要截断的undo表空间的选择方式为循环选择来避免同一时间截断相同的undo表空间.
驻留在被选择的undo表空间中的回滚段会被变为非活动状态来防止不将其分配给新的事务.当前回滚段的事务允许执行到结束.
清理(purge)系统释放不再使用的回滚段.
当undo表空间的所有回滚段都释放之后,截断操作就会执行将undo表空间截断到初始化的大小.undo表空间的初始化大小由 innodb_page_size决定.对于默认的16KB页面大小,undo表空间的初始值是10Mib.对4KB,8KB, 32KB和64KB的页面大小,undo表空间的初始大小是7MiB,8MiB,20MiB,和40MiB.
如果在截断操作完成后立即使用,undo表空间的大小可能会比初始化的大小更大.
innodb_undo_directory变量定义了undo表空间文件的位置.如果 innodb_undo_directory变量未定义,undo表空间就在数据目录下.
重新启用回滚段以便分配给新的事务.
加速undo表空间截断(Expediting Truncation of Undo Tablespaces)
清除(purge)线程负责清空和截断undo表空间.默认情况下,清除线程查找需要截断的undo表空间,每隔128次查找就清除一次.清除线程查找要截断的undo表空间的频率由innodb_purge_rseg_truncate_frequency变量控制,默认是128.
1 2 3 4 5 6 mysql> SELECT @@innodb_purge_rseg_truncate_frequency ; + | @@innodb_purge_rseg_truncate_frequency | + | 128 | +
为了增加频率需要减小 innodb_purge_rseg_truncate_frequency的值.例如你想每32次查找就调用一次清除的话,设置 innodb_purge_rseg_truncate_frequency为32.
1 mysql> SET GLOBAL innodb_purge_rseg_truncate_frequency= 32 ;
截断undo表空间文件的性能影响(Performance Impact of Truncating Undo Tablespace Files)
当一个undo表空间被截断时,上面的回滚段已经被停用.其他表空间中活动的回滚段会承担整个系统的负载,这可能导致系统性能略有下降.性能下降的程度取决于很多因素:
undo表空间的数量.
undo日志的数量.
undo表空间的大小.
I/O部分的速度.
是否存在正在运行的长事务.
系统负载.
避免截断撤销表空间时对性能影响最简单的方法是增加表空间的数量.
14.6.3.5 临时表空间(The Temporary Tablespace) 非压缩的用户创建的临时表和磁盘内部临时表被创建在共享临时表空间内.innodb_temp_data_file_path配置定义了临时表空间数据文件的相关路径,名称,大小和属性.如果没有给innodb_temp_data_file_path指定值,默认会在 innodb_data_home_dir目录下创建一个略大于12MB的自动扩展的名为ibtmp1的数据文件.
可压缩的临时表是用ROW_FORMAT=COMPRESSED属性创建的临时表,是在临时文件目录的单表单文件表空间中创建的.
临时表空间在正常关闭和终止初始化的时候被删除,并在每次服务器启动时重新创建.临时表空间在创建时获得一个动态生成的空间ID.如果无法创建临时表空间就不能启动.如果服务器意外终止的话临时表空间是不会删除的.在这种情况下,数据库管理员可以手动删除临时表空间或重启服务器,都可以自动地删除和重建临时表空间.
临时表空间不能驻留在原始设备上.
INFORMATION_SCHEMA.FILES提供了关于InnoDB临时表的元数据.执行下面的简单查询来查看临时表空间的元数据.
1 mysql> SELECT * FROM INFORMATION_SCHEMA.FILES WHERE TABLESPACE_NAME= 'innodb_temporary' \G
INFORMATION_SCHEMA.INNODB_TEMP_TABLE_INFO提供了现在还在InnoDB实例中活跃的由用户创建的临时表的元数据.
管理临时表空间数据文件的大小
默认情况下,临时表空间数据文件是自动扩展的,并且根据需要增加大小以容纳磁盘上的临时表.例如,如果一个操作创建了一个20MB的临时表,默认创建的12MB大小的临时表空间会自动扩大以适应它.当临时表被删除的时候,释放的空间可以被新的临时表使用,但是数据文件仍然保留扩展之后的大小.
在使用大型临时表或广泛使用临时表的情况下自动扩展的临时表数据文件会变得很大.大的数据文件也可能是使用临时表执行一个长时间运行的查询造成的.
检查 innodb_temp_data_file_path设置来决定临时表空间数据文件是否要自动扩展:
1 2 3 4 5 6 mysql> SELECT @@innodb_temp_data_file_path ; + | @@innodb_temp_data_file_path | + | ibtmp1:12 M:autoextend | +
查询 INFORMATION_SCHEMA.FILES表来检查临时表空间数据文件的大小:
1 2 3 4 5 6 7 8 9 10 11 mysql> SELECT FILE_NAME, TABLESPACE_NAME, ENGINE, INITIAL_SIZE, TOTAL_EXTENTS* EXTENT_SIZE AS TotalSizeBytes, DATA_FREE, MAXIMUM_SIZE FROM INFORMATION_SCHEMA.FILES WHERE TABLESPACE_NAME = 'innodb_temporary' \G * * * * * * * * * * * * * * * * * * * * * * * * * * * 1. row * * * * * * * * * * * * * * * * * * * * * * * * * * * FILE_NAME: ./ ibtmp1 TABLESPACE_NAME: innodb_temporary ENGINE: InnoDB INITIAL_SIZE: 12582912 TotalSizeBytes: 12582912 DATA_FREE: 6291456 MAXIMUM_SIZE: NULL
TotalSizeBytes的值表示当前临时表空间数据文件的大小.
另外,在你的操作系统上检查临时表空间的数据文件大小.默认情况下,临时表空间数据文件位于 innodb_temp_data_file_path定义的目录下.如果没有指定该值,一个名为ibtmp1的临时表空间数据文件创建在innodb_data_home_dir下,默认情况下为MySQL数据文件夹.
要回收临时表空间数据文件占用的磁盘空间,要重新启动MySQL服务器.重新启动服务器将根据innodb_temp_data_file_path定义的属性删除并重新创建临时表空间数据文件.
要防止临时数据文件变得太大,可以配置innodb_temp_data_file_path选项以指定最大文件大小.例如:
1 2 [mysqld] innodb_temp_data_file_path= ibtmp1:12 M:autoextend:max:500 M
当数据文件达到最大大小时,查询会失败并显示一个表已满的错误.配置innodb_temp_data_file_path需要重新启动服务器.
另外,配置default_tmp_storage_engine和internal_tmp_disk_storage_engine选项,分别定义用于用户创建的和磁盘内部临时表的存储引擎.默认情况下,这两个选项都设置为InnoDB. MyISAM存储引擎为每个临时表使用单个文件,在删除临时表时将删除该文件.
14.6.3.6 在数据文件外创建表空间 CREATE TABLE ... DATA DIRECTORY语句允许在数据目录之外创建单表单文件表空间.例如,你可以用DATA DIRECTORY 语句在特定性能或容量的单独的存储设备上创建表空间,例如快速的SSD或者大容量的HDD.
确定你选择的位置没有问题.DATA DIRECTORY子句不能和 ALTER TABLE一起使用来改变位置.
表空间数据文件创建在指定的目录里,每个表都会有一个以表名命名的子目录.包含表空间目录的.isl文件创建在子目录下.可以把.isl视为符号链接.
下面的示例演示了在数据目录之外创建一个单表单文件表空间.假定 innodb_file_per_table变量是默认的.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 mysql> USE test; Database changed mysql> CREATE TABLE t1 (c1 INT PRIMARY KEY ) DATA DIRECTORY = '/remote/directory' ; # MySQL creates the tablespace file in a subdirectory that is named # for the schema to which the table belongs shell> cd / remote/ directory/ test shell> ls t1.ibd # In the schema directory, MySQL creates an isl file that defines # the tablespace path shell> cd / path/ to / mysql/ data/ test shell> ls db.opt t1.frm t1.isl
CREATE TABLE ... TABLESPACE语句也可以和DATA DIRECTORY 子句组合在数据目录外创建一个单表单文件表空间.要这样做的话,指定innodb_file_per_table作为表空间名.
1 2 mysql> CREATE TABLE t2 (c1 INT PRIMARY KEY ) TABLESPACE = innodb_file_per_table DATA DIRECTORY = '/remote/directory' ;
使用此方法时不需要启用 innodb_file_per_table变量.
使用说明
MySQL最初保持表空间数据文件打开,阻止卸载设备,但如果服务器忙,最终可能会关闭表.注意不要在MySQL运行时意外卸载外部设备,或在设备断开连接时启动MySQL.在关联的表空间数据文件丢失时尝试访问表会导致严重错误,需要重新启动服务器.
如果表空间数据文件文件不在预期路径服务器重新启动可能会失败.在这种情况下,请从目录中手动删除isl文件,并在重新启动后删除该表以从数据字典中删除.frm文件和有关该表的信息.
在将表空间放在已安装NFS的卷上之前,请查看使用NFS与MySQL中列出的潜在问题.
如果使用LVM快照,文件复制或其他基于文件的机制来备份表空间数据文件,首先使用FLUSH TABLES ... FOR EXPORT语句确保在备份之前将缓冲在内存中的所有更改都刷新到磁盘.
不支持使用DATA DIRECTORY子句视作使用符号链接的替代方法.
14.6.3.7 复制表空间到其他实例 这个部分描述如何把单表单文件表空间从一个MySQL实例复制到另一个实例,也称为可传输表空间.
有许多理由可能导致你要复制一个InnoDB单表单文件表空间到另一个实例:
在不对生产服务器施加额外负载的情况下运行报告.
在新的slave服务器上对表设置相同的数据.
在出现问题或错误后恢复备份版本的表或分区.
作为一种更快速的数据移动方式,比使用mysqldump导入更快.数据立即可用并且不用重新插入和重建索引.
将单表单文件表空间移动到具有更适合系统要求的存储介质的服务器.例如你想把频繁操作的表放在SSD上或把大型表放到大容量的HDD上.
局限性和使用注意(Limitations and Usage Notes)
只有在 innodb_file_per_table设置为ON时才能进行表空间复制(默认设置).驻留在系统表空间中的表不能停顿.
当一个表停顿的时候,该表上只允许只读事务.
当导入表空间时,页面大小必须和导入的实例的页面大小匹配.
当 foreign_key_checks设置为1时,有父子关系(主键-外键)的表空间不支持DISCARD TABLESPACE.在丢弃父子表的表空间之前,需要设置foreign_key_checks = 0.分区的InnoDB表不支持外键.
ALTER TABLE ... IMPORT TABLESPACE在导入数据时不强制外键约束.如果表之间有外键约束,所有的表应该在同一个时间节点(逻辑上)进行导出.分区的InnoDB表不支持外键.ALTER TABLE ... IMPORT TABLESPACE和 ALTER TABLE ... IMPORT PARTITION ... TABLESPACE不需要.cfg元数据来导入表空间.但是,在没有.cfg文件的情况下导入时元数据检查不会执行,并发出类似下面的警告: 1 2 3 Message: InnoDB: IO Read error: (2, No such file or directory) Error opening '.\ test\t.cfg', will attempt to import without schema verification 1 row in set (0.00 sec)
因为.cfg元数据文件的限制,导入分区表的表空间文件时,不会报告分区类型或分区定义差异的模式不匹配.列的差异会被报告.
在子分区表上运行 ALTER TABLE ... DISCARD PARTITION ... TABLESPACE和 ALTER TABLE ... IMPORT PARTITION ... TABLESPACE时,允许分区和子分区的表名.当指定分区名时,分区的子分区会被包含到操作中.
如果两个实例都具有GA(General Availability)状态且其版本在同一系列中,则可以从另一个MySQL服务器实例导入表空间文件.否则,必须在导入该文件的同一服务器实例上创建该文件.
在复制时,master和slave上的 innodb_file_per_table必须设置为ON.
在Windows上,InnoDB隐式使用小写存储数据库,表空间和表名.为了避免在大小写敏感的操作系统上(如Linux和UNIX)产生导入错误,使用小写来创建所有的数据库,表空间和表名.一个方便的办法是在创建数据库,表空间或表之前在my.cnf或my.ini的[mysqld]部分下添加下面的行: 1 2 [mysqld] lower_case_table_names=1
ALTER TABLE ... DISCARD TABLESPACE和 ALTER TABLE ...IMPORT TABLESPACE不支持属于InnoDB通用表空间的表.InnoDB的默认行格式使用innodb_default_row_format 配置选项.导入未明确定义行格式(ROW_FORMAT)的表或使用ROW_FORMAT = DEFAULT的表,如果源实例上的innodb_default_row_format设置与目标实例上的设置不同,可能导致模式不匹配错误.
导出使用InnoDB表空间加密功能加密的表空间时,除了.cfg元数据文件外,InnoDB还会生成.cfp文件.在目标实例上执行ALTER TABLE ... IMPORT TABLESPACE操作之前,需要把.cfp文件和.cfg文件一起复制到目标实例上..cfp文件包含传输密钥和加密的表空间密钥.在导入时,InnoDB使用传输密钥来解密表空间密钥.
FLUSH TABLES ... FOR EXPORT不支持有全文索引的表.全文搜索辅助表不会刷新.在导入有全文索引的表后,执行 OPTIMIZE TABLE来重建全文索引.或者在导出操作之前删除全文索引,并在导入目标实例上的表后重新创建.
14.6.3.7.1 传输表空间例子 Example 1: 复制InnoDB表到另一个实例
此过程演示如何将常规InnoDB表从正在运行的MySQL服务器实例复制到另一个正在运行的实例.可以使用具有微小调整的相同过程在同一实例上执行完整表还原.
在源实例上,创建表(如果不存在): 1 2 mysql> USE test; mysql> CREATE TABLE t(c1 INT ) ENGINE= InnoDB;
在目标实例上,创建表(如果不存在): 1 2 mysql> USE test; mysql> CREATE TABLE t(c1 INT ) ENGINE= InnoDB;
在目标实例上丢弃存在的表空间: 1 mysql> ALTER TABLE t DISCARD TABLESPACE;
在源实例上,运行 FLUSH TABLES ... FOR EXPORT来停顿表然后创建.cfg元数据文件. 1 2 mysql> USE test; mysql> FLUSH TABLES t FOR EXPORT;
从源实例复制.ibd文件和.cfg文件到目标实例,例如: 1 shell> scp /path/to/datadir/test/t.{ibd,cfg} destination-server:/path/to/datadir/test
在源实例上,使用 UNLOCK TABLES释放 FLUSH TABLES ... FOR EXPORT获取的锁: 1 2 mysql> USE test; mysql> UNLOCK TABLES;
在目标实例上,导入表空间: 1 2 mysql> USE test; mysql> ALTER TABLE t IMPORT TABLESPACE;
Example 2: 复制InnoDB分区表到另一个实例
此过程演示如何将分区的InnoDB表从正在运行的MySQL服务器实例复制到另一个正在运行的实例.可以使用具有微小调整的相同过程在同一实例上执行分区InnoDB表的完全恢复.
在源实例上,创建分区表(如果不存在).下面的例子中一个表创建了3个分区(p0,p1,p2): 1 2 mysql> USE test; mysql> CREATE TABLE t1 (i int ) ENGINE = InnoDB PARTITION BY KEY (i) PARTITIONS 3 ;
/datadir/test目录下,三个分区都有单独的.ibd文件: 1 2 mysql> \! ls /path/to/datadir/test/ db.opt t1.frm t1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd
在目标实例上创建相同的分区表: 1 2 mysql> USE test; mysql> CREATE TABLE t1 (i int ) ENGINE = InnoDB PARTITION BY KEY (i) PARTITIONS 3 ;
/datadir/test目录下,三个分区都有单独的.ibd文件: 1 2 mysql> \! ls /path/to/datadir/test/ db.opt t1.frm t1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd
在目标实例上丢弃分区表表空间 1 mysql> ALTER TABLE t1 DISCARD TABLESPACE;
/datadir/test中丢弃,留下以下文件: 1 2 mysql> \! ls /path/to/datadir/test/ db.opt t1.frm
在源实例上,运行 FLUSH TABLES ... FOR EXPORT来停顿表然后创建.cfg元数据文件. 1 2 mysql> USE test; mysql> FLUSH TABLES t FOR EXPORT;
1 2 3 mysql> \! ls / path/ to / datadir/ test/ db.opt t1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd t1.frm t1#P#p0.cfg t1#P#p1.cfg t1#P#p2.cfg
从源实例复制.ibd文件和.cfg文件到目标实例,例如: 1 shell>scp /path/to/datadir/test/t1*.{ibd,cfg} destination-server:/path/to/datadir/test
在源实例上,使用 UNLOCK TABLES释放 FLUSH TABLES ... FOR EXPORT获取的锁: 1 2 mysql> USE test; mysql> UNLOCK TABLES;
在目标实例上,导入表空间: 1 2 mysql> USE test; mysql> ALTER TABLE t IMPORT TABLESPACE;
Example 3: 复制InnoDB表分区到另一个实例
此过程演示如何将InnoDB表分区从正在运行的MySQL服务器实例复制到另一个正在运行的实例.可以使用具有微小调整的相同过程在同一实例上执行InnoDB表分区的还原.在下面的示例中,将在源实例上创建具有四个分区(p0,p1,p2,p3)的分区表.其中两个分区(p2和p3)被复制到目标实例.
在源实例上,创建分区表(如果不存在).下面的例子中一个表创建了4个分区(p0,p1,p2,p3): 1 2 mysql> USE test; mysql> CREATE TABLE t1 (i int ) ENGINE = InnoDB PARTITION BY KEY (i) PARTITIONS 4 ;
/datadir/test目录下,四个分区都有单独的.ibd文件: 1 2 mysql> \! ls /path/to/datadir/test/ db.opt t1.frm t1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd t1#P#p3.ibd
在目标实例上创建相同的分区表: 1 2 mysql> USE test; mysql> CREATE TABLE t1 (i int ) ENGINE = InnoDB PARTITION BY KEY (i) PARTITIONS 4 ;
/datadir/test目录下,四个分区都有单独的.ibd文件: 1 2 mysql> \! ls /path/to/datadir/test/ db.opt t1.frm t1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd t1#P#p3.ibd
在目标实例上丢弃计划要从源实例上导入的表空间分区. 1 mysql> ALTER TABLE t1 DISCARD PARTITION p2, p3 TABLESPACE;
1 2 mysql> \! ls /path/to/datadir/test/ db.opt t1.frm t1#P#p0.ibd t1#P#p1.ibd
在源实例上,运行 FLUSH TABLES ... FOR EXPORT来停顿表然后创建.cfg元数据文件. 1 2 mysql> USE test; mysql> FLUSH TABLES t FOR EXPORT;
1 2 3 mysql> \! ls /path/to/datadir/test/ db.opt t1#P#p0.ibd t1#P#p1.ibd t1#P#p2.ibd t1#P#p3.ibd t1.frm t1#P#p0.cfg t1#P#p1.cfg t1#P#p2.cfg t1#P#p3.cfg
从源实例复制.ibd文件和.cfg文件到目标实例.在这个例子中,只需要复制分区2(p2)和分区3(p3)的.ibd和.cfg文件. 1 shell> scp t1#P#p2.ibd t1#P#p2.cfg t1#P#p3.ibd t1#P#p3.cfg destination-server:/path/to/datadir/test
在源实例上,使用 UNLOCK TABLES释放 FLUSH TABLES ... FOR EXPORT获取的锁: 1 2 mysql> USE test; mysql> UNLOCK TABLES;
在目标实例上,导入表空间: 1 2 mysql> USE test; mysql> ALTER TABLE t IMPORT TABLESPACE;
14.6.3.7.2 可传输表空间内幕 以下信息描述了常规InnoDB表的可传输表空间复制过程的内部和错误日志消息传递.
当 ALTER TABLE ... DISCARD TABLESPACE运行在目标实例上时:
当 FLUSH TABLES ... FOR EXPORT运行在源实例上时:
刷新后正在导出的表在共享模式下被锁定.
清除(purge)协调器线程已停止.
脏页面同步到磁盘.
表元数据被写到二进制.cfg文件.
操作可能导致下面的预期错误:
1 2 3 4 2013-09-24T13:10:19.903526Z 2 [Note] InnoDB: Sync to disk of '"test"."t"' started. 2013-09-24T13:10:19.903586Z 2 [Note] InnoDB: Stopping purge 2013-09-24T13:10:19.903725Z 2 [Note] InnoDB: Writing table metadata to './test/t.cfg' 2013-09-24T13:10:19.904014Z 2 [Note] InnoDB: Table '"test"."t"' flushed to disk
当UNLOCK TABLES在源实例上运行时:
二进制.cfg文件被删除.
正在导入的表或表上的共享锁被释放并且清除协调器线程重新启动.
操作可能导致下面的预期错误:
1 2 2013-09-24T13:10:21.181104Z 2 [Note] InnoDB: Deleting the meta-data file './test/t.cfg' 2013-09-24T13:10:21.181180Z 2 [Note] InnoDB: Resuming purge
当ALTER TABLE ... IMPORT TABLESPACE运行在目标实例上时,导入算法对要导入的每个表空间执行以下操作:
检查每个表空间页面是否损坏.
每页上的空间ID和日志序列号(LSN)都会更新.
验证标志并更新起始页的LSN.
B树页被更新.
页面状态设置为脏,以便将其写入磁盘.
操作可能导致下面的预期错误:
1 2 3 4 5 6 2013-07-18 15:15:01 34960 [Note] InnoDB: Importing tablespace for table 'test/t' that was exported from host 'ubuntu' 2013-07-18 15:15:01 34960 [Note] InnoDB: Phase I - Update all pages 2013-07-18 15:15:01 34960 [Note] InnoDB: Sync to disk 2013-07-18 15:15:01 34960 [Note] InnoDB: Sync to disk - done! 2013-07-18 15:15:01 34960 [Note] InnoDB: Phase III - Flush changes to disk 2013-07-18 15:15:01 34960 [Note] InnoDB: Phase IV - Flush complete
14.6.3.8 InnoDB表空间加密 (大致为机翻,没有太关注这部分内容)
表空间加密使用双层加密密钥体系结构,由主加密密钥和表空间密钥组成.当表空间被加密时,表空间密钥被加密并存储在表空间头中.当应用程序或经过身份验证的用户想要访问加密的表空间数据时,InnoDB使用主加密密钥来解密表空间密钥.表空间密钥的解密版本永远不会更改,但可以根据需要更改主加密密钥.此操作称为主密钥轮换.
表空间加密功能依赖于用于主加密密钥管理的密钥环插件.
所有MySQL版本都提供了一个keyring_file插件,它将密钥环数据存储在服务器主机本地的文件中.
MySQL企业版提供额外的密钥环插件:
keyring_encrypted_file插件,用于将密钥环数据存储在服务器主机本地的加密文件中.
keyring_okv插件,包括KMIP客户端(KMIP 1.1),该客户端使用兼容KMIP的产品作为密钥环存储的后端.支持KMIP的兼容产品包括集中式密钥管理解决方案,如Oracle Key Vault,Gemalto KeySecure,Thales Vormetric密钥管理服务器和Fornetix Key Orchestration.
keyring_aws插件,与Amazon Web Services密钥管理服务(AWS KMS)通信,作为密钥生成的后端,并使用本地文件进行密钥存储.
安全可靠的加密密钥管理解决方案对于安全性和遵守各种安全标准至关重要.当表空间加密功能使用集中式密钥管理解决方案时,该功能称为”MySQL企业透明数据加密(TDE)”.
表空间加密支持基于高级加密标准(AES)块的加密算法.它使用电子密码本(ECB)块加密模式进行表空间密钥加密,使用密码块链接(CBC)块加密模式进行数据加密.
InnoDB表空间加密要求(InnoDB Tablespace Encryption Prerequisites)
必须安装和配置密钥环插件.Keyring插件安装在启动时使用early-plugin-load选项执行.早期加载可确保在InnoDB存储引擎初始化之前插件可用.
一次只能启用一个密钥环插件.不支持启用多个密钥环插件.
要验证密钥环插件是否处于活动状态,请使用SHOW PLUGINS语句或查询INFORMATION_SCHEMA.PLUGINS表.例如:
1 2 3 4 5 6 7 8 mysql> SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME LIKE 'keyring%' ; + | PLUGIN_NAME | PLUGIN_STATUS | + | keyring_file | ACTIVE | +
仅对每个表的文件表空间支持加密.要在每个表的文件表空间中创建一个表,请确保在执行CREATE TABLE语句之前启用了innodb_file_per_table(默认值).或者,在CREATE TABLE语句中使用TABLESPACE =’innodb_file_per_table’子句.
加密生产数据时,请确保采取措施防止丢失主加密密钥.如果主加密密钥丢失,则存储在加密表空间文件中的数据将无法恢复 .如果使用keyring_file或keyring_encrypted_file插件,请在创建第一个加密表空间之后,主密钥轮换之前以及主密钥轮换之后立即创建密钥环数据文件的备份.keyring_file_data配置选项定义keyring_file插件的密钥环数据文件位置.keyring_encrypted_file_data配置选项定义keyring_encrypted_file插件的密钥环数据文件位置.如果使用keyring_okv或keyring_aws插件,请确保已执行必要的配置.
启用或禁用单表单文件表空间加密
要为新的单表单文件表空间启用加密,请在CREATE TABLE语句中指定ENCRYPTION选项
1 mysql> CREATE TABLE t1 (c1 INT) ENCRYPTION='Y';
要为现有的单表单文件表空间启用加密,请在ALTER TABLE语句中指定ENCRYPTION选项.
1 mysql> ALTER TABLE t1 ENCRYPTION='Y';
要禁用单表单文件表空间的加密,请使用ALTER TABLE设置ENCRYPTION =’N’.
1 mysql> ALTER TABLE t1 ENCRYPTION='N';
InnoDB表空间加密和主密钥轮换
只要您怀疑密钥已被泄露,就应定期轮换主加密密钥.
主密钥轮换是一种原子的实例级操作.每次旋转主加密密钥时,MySQL实例中的所有表空间键都会重新加密并保存回各自的表空间头. 作为原子操作,一旦启动旋转操作,所有表空间键的重新加密必须成功.如果服务器故障导致主密钥轮换中断,则InnoDB会在服务器重新启动时向前滚动操作.
旋转主加密密钥只会更改主加密密钥并重新加密表空间密钥.它不会解密或重新加密关联的表空间数据.
旋转主加密密钥需要SUPER权限.
要旋转主加密密钥,运行:
1 mysql> ALTER INSTANCE ROTATE INNODB MASTER KEY;
ALTER INSTANCE ROTATE INNODB MASTER KEY支持并发DML.但是,它不能与表空间加密操作同时运行,并且会采取锁定来防止可能由并发执行引起的冲突.如果ALTER INSTANCE ROTATE INNODB MASTER KEY操作正在运行,则必须在表空间加密操作继续之前完成,反之亦然.
InnoDB表空间加密和恢复(InnoDB Tablespace Encryption and Recovery)
如果在加密操作期间发生服务器故障,则在重新启动服务器时前滚操作.
如果在主密钥轮换期间发生服务器故障,InnoDB将继续执行服务器重新启动操作.
必须在存储引擎初始化之前加载密钥环插件,以便在InnoDB初始化和恢复活动访问表空间数据之前,可以从表空间头中检索解密表空间数据页所需的信息.
当InnoDB初始化和恢复开始时,主密钥轮换操作重新开始.由于服务器故障,某些表空间密钥可能已使用新的主加密密钥加密.InnoDB从每个表空间头读取加密数据,如果数据表明表空间密钥使用旧的主加密密钥加密,InnoDB从密钥环检索旧密钥并使用它来解密表空间密钥.InnoDB然后使用新的主加密密钥重新加密表空间密钥,并将重新加密的表空间密钥保存回表空间头.
导出加密表空间
导出加密表空间时,InnoDB会生成一个用于加密表空间密钥的传输密钥.加密的表空间密钥和传输密钥存储在tablespace_name.cfp文件中.需要此文件和加密的表空间文件才能执行导入操作.导入时,InnoDB使用传输密钥解密tablespace_name.cfp文件中的表空间键.
InnoDB表空间加密和复制
ALTER INSTANCE ROTATE INNODB MASTER KEY语句仅在主服务器和从服务器运行支持表空间加密的MySQL版本的复制环境中受支持.成功的ALTER INSTANCE ROTATE INNODB MASTER KEY语句被写入二进制日志以便在从站上进行复制.
如果ALTER INSTANCE ROTATE INNODB MASTER KEY语句失败,则不会记录到二进制日志中,也不会在从属服务器上复制.
如果密钥环插件安装在主服务器而不是从服务器上,则复制ALTER INSTANCE ROTATE INNODB MASTER KEY操作失败.
如果主服务器和从服务器上都安装了keyring_file或keyring_encrypted_file插件,但是从服务器没有密钥环数据文件,则复制的ALTER INSTANCE ROTATE INNODB MASTER KEY语句会在从服务器上创建密钥环数据文件,假设密钥环文件数据为没有缓存在内存中.ALTER INSTANCE ROTATE INNODB MASTER KEY使用缓存在内存中的密钥环文件数据(如果有).
识别加密表空间
在CREATE TABLE或ALTER TABLE语句中指定ENCRYPTION选项时,它将记录在INFORMATION_SCHEMA.TABLES的CREATE_OPTIONS列中.可以查询此列以标识驻留在加密的每个表文件表空间中的表.
1 2 3 4 5 6 7 mysql> SELECT TABLE_SCHEMA, TABLE_NAME, CREATE_OPTIONS FROM INFORMATION_SCHEMA.TABLES WHERE CREATE_OPTIONS LIKE '%ENCRYPTION%' ; + | TABLE_SCHEMA | TABLE_NAME | CREATE_OPTIONS | + | test | t1 | ENCRYPTION= "Y" | +
查询INFORMATION_SCHEMA.INNODB_SYS_TABLESPACES以检索有关与特定架构和表关联的表空间的信息.
1 2 3 4 5 6 mysql> SELECT SPACE, NAME, SPACE_TYPE FROM INFORMATION_SCHEMA.INNODB_SYS_TABLESPACES WHERE NAME= 'test/t1' ; + | SPACE | NAME | SPACE_TYPE | + | 3 | test/ t1 | Single | +
InnoDB表空间加密使用说明
使用ENCRYPTION选项更改现有表空间时,请进行适当规划.使用COPY算法重建该表.不支持INPLACE算法.
如果服务器在正常操作期间退出或停止,建议使用先前配置的相同加密设置重新启动服务器.
当第一个新表空间或现有表空间被加密时,将生成第一个主加密密钥.
主密钥轮换重新加密表空间密钥,但不会更改表空间密钥本身.要更改表空间键,必须禁用并重新启用加密,这是一个重建表的ALGORITHM = COPY操作.
如果使用COMPRESSION和ENCRYPTION选项创建表,则在加密表空间数据之前执行压缩.
如果密钥环数据文件(由keyring_file_data或keyring_encrypted_file_data命名的文件)为空或丢失,则首次执行ALTER INSTANCE ROTATE INNODB MASTER KEY会创建主加密密钥.
卸载keyring_file或keyring_encrypted_file插件不会删除现有的密钥环数据文件.
建议您不要将密钥环数据文件放在与表空间数据文件相同的目录下.
在运行时或重新启动服务器时修改keyring_file_data或keyring_encrypted_file_data设置可能导致以前加密的表空间无法访问,从而导致数据丢失.
InnoDB表空间加密的限制
高级加密标准(AES)是唯一受支持的加密算法.InnoDB表空间加密使用电子密码本(ECB)块加密模式进行表空间密钥加密和密码块链接(CBC)块加密模式进行数据加密.
使用COPY算法更改表的ENCRYPTION属性.不支持INPLACE算法.
仅对每个表的文件表空间支持加密.其他表空间类型(包括通用表空间和系统表空间)不支持加密.
你不能将表从加密的每表表空间移动或复制到不支持加密的表空间类型.
表空间加密仅适用于表空间中的数据.数据未在重做日志,撤消日志或二进制日志中加密.
不允许更改驻留或先前驻留在加密表空间中的表的存储引擎.