写在前面 之前也是写了一篇这周搞的一些新东西 ,其实当时就是看了V2站长开始写周报也有了点想法但是想想似乎每周也没有那么多可写的内容,就先随便写了一篇.但是最近也算是有点清闲又骚了很多新的东西就不免想要记录一下,正好趁着给博客重新进行了一波整理分类之后也是下了开始写周报的决心吧,但是频率可能也就是2周或者3周记录和总结一下.
ps. 目前格式就按照事情来排列然后加以描述
v2ray 在经历了一系列不可描述的会议之后,在2个星期前我的hk服务器算是终于又通了$$了,但是鉴于封杀时的效率还是有点怕自己的ip被封了的,所以就趁着摸鱼的时光研究了一下v2ray.当然不是深入研究,最开始是找了一个一键部署的脚本,也就是填一下配置就能直接用了感觉还是很不错的.
V2Ray一键安装脚本
HTTP/2 在后来看了这个v2ray-HTTP/2 之后发现HTTP/2似乎是很”香”就打算尝试一下,但是:
与其它的传输层协议一样在 streamSettings 中配置,不过要注意的是使用 HTTP/2 要开启 TLS。
似乎是要上HTTPS了,鉴于现在的域名还用在博客上就又重新申请了一个域名用来申请一个免费的HTTPS证书然后用来配置HTTP/2.
CDN
Cloudflare 还是太慢了,用国内的吧,绝对能体验飞一般的速度,正好 V2Ray 已经支持 HTTP/2 了,又拍云、七牛、阿里都不错,腾讯的 h2 还在内测,百度不清楚。不过说真的,CDN 的话国外的还是有些水土不服,强烈建议使用国内的,速度提升非常大,也非常稳定,高峰期毫无压力,在重点 IP 段也无所畏惧。
就是跟着上面的HTTP/2又顺势看了CDN,想的是如果能使用国内CDN的话岂不是速度能快的飞起(毕竟现在延迟有200ms左右),但是在看了国内免费CDN对比与申请部署教程 之后尝试了一下又拍云才发现:国内的备案太痛苦了!!! .并且阿里云的备案要求购买轻量应用服务器续费3个月以上,但是在我续费之后仍然不能申请备案服务号也就放弃了,还是选择了cloudflare.
v2-ui 是在看拯救被墙的IP,CDN + v2ray,安全的科学上网方法 这篇博客的时候发现的,发现比一键部署脚本还是挺不错的毕竟有GUI可以用来动态配置.
现在的v2ray配置 大致的流程:
使用cloudflare来解析域名(修改DNS)
添加一个A解析指向v2ray的ip,Name自己填写,我使用了www
在SSL/TLS选项卡中选择Full(Encrypts end-to-end, using a self signed certificate on the server)
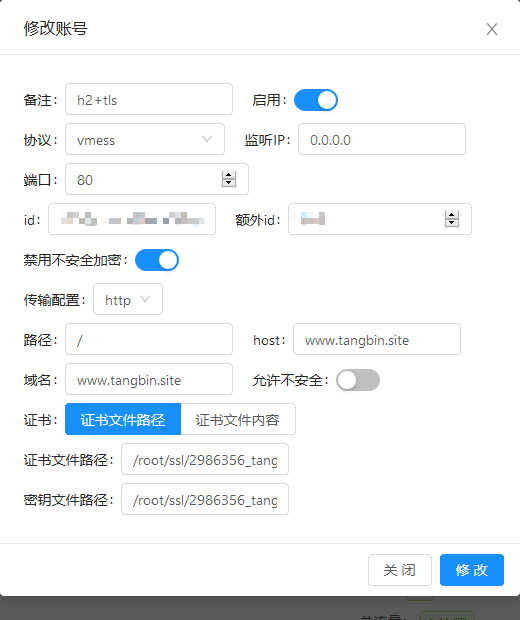
在v2-ui中新建一个账号,端口使用了80(玄学:因为大部分网站都使用80端口做web服务所以不容易被侦测),配置http(就是http/2),host和域名都填了上面解析的域名,然后选择申请的免费ssl证书
导出配置
下面是我的配置截图:
Aria2+Filebrowser 有了服务器就会开始折腾,因为自己电脑挂bt有点慢而且AMD出名的功耗高也不想因为下个视频就一直开着于是就想到在服务器上在整一个Aria来挂bt然后再来一个远程播放岂不美哉?
当然有轮子是最好的,于是就找到了:使用Docker安装Aria2+AriaNg+Filebrowser,可离线BT下载/在线播放 ,直接docker run 非常不错:
1 docker run --name ccaa -d -p 6800:6800 -p 6080:6080 -v /home/root/aria-download:/Down moerats/ccaa:latest
当然-v不是必要的,这是为了后面做铺垫
NextCloud
Nextcloud是一套用于创建网络硬盘的客户端-服务器软件。其功能与Dropbox相近,但Nextcloud是自由及开放源代码软件,每个人都可以在私人服务器上安装并运行它。
与Dropbox等专有服务相比,Nextcloud的开放架构让用户可以利用应用程序的方式在服务器上新增额外的功能,并让用户可以完全掌控自己的数据。
Nextcloud用户可以管理日历(使用CalDAV)、联系人(CardDAV)、计划工作与流媒体(Ampache)。
从管理的角度来看,Nextcloud允许用户与组群管理(透过OpenID或LDAP)。透过用户间与/或组群间的读/写权限调整达到分享文件的目的。另外,Nextcloud的用户可以创建公开的URL来分享文件。也可以记录与文件相关的动作,以及利用文件访问规则来禁止对特定文件的访问[2]。
此外,用户也可以透过浏览器使用Nextcloud的文本编辑器、书签服务、缩略网址服务、相册、RSS阅读器与文件查看器。因为有良好的扩展性,Nextcloud可以透过鼠标点一下即可完成安装的应用程序强化其功能,并可连线至Dropbox、Google云端硬盘与Amazon S3。 ————来自维基百科
上面的-v当然是这里用到了,原因是有些视频格式对于Filebrowser来说太难了,并不能正确的解析,在线观看也就无从说起了.所以在一番调研之后决定在为了能看视频的同时顺便尝试一下这私人网盘是什么感觉的.
当然还是方便的docker部署了:
1 docker run -d --restart=always --name nextcloud -p 8888:80 -v /root/nextcloud:/data -v /home/root/aria-download:/aria docker.io/nextcloud
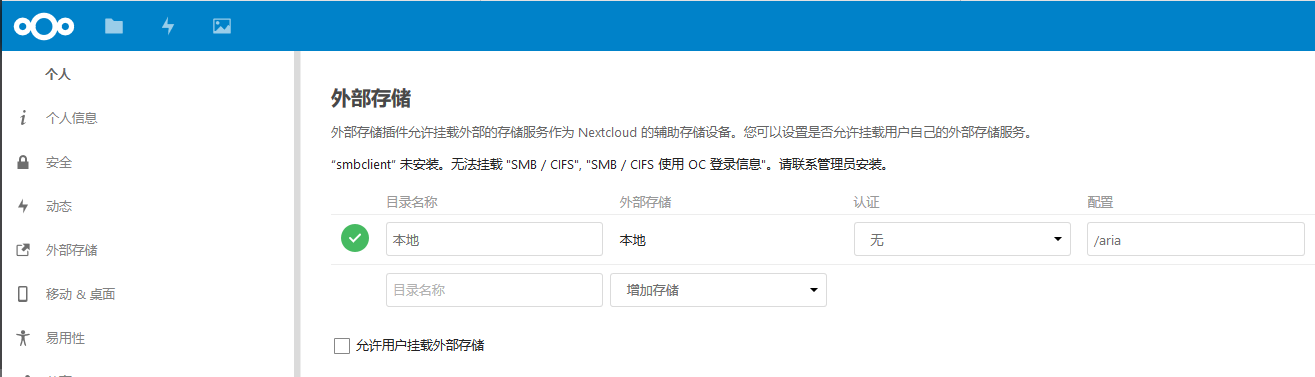
然后在NextCloud挂载外部存储就可以了.
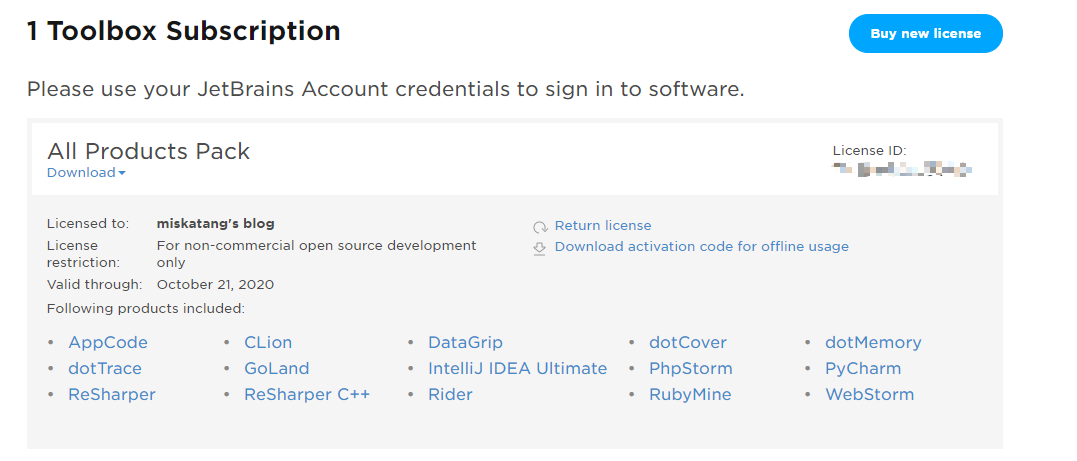
JetBrains 免费License 在毕业几个月之后终于意识到:我的学生邮箱没了,也就是说不能再白嫖好用的idea了(才怪),在琢磨了一番之后发现了官方的面向开发者的免费许可:Open Source License Request ,于是就用这个博客项目尝试了一波,一开始也是没有抱多大希望的,毕竟项目没人star也没人fork,但是在几天之后收到了:
于是就快乐的激活了许可:
虽然感觉还是受之有愧,但是毕竟JB对开发者这么好也就只能收下这份许可来继续激励我写博客吧.
咖啡 不知道是什么时候养成的习惯吧,但是现在似乎是已经离不开咖啡了,之前的出租房地方比较小的时候还是喝一喝挂耳咖啡,在这次搬家之后也是空间Dark♂了很多然后就趁着双11入了一个法压壶+咖啡豆,一是挂耳确实有点贵,买咖啡豆的话买些意式拼配的豆子也是比挂耳便宜了许多,再者也是想尝试一下是不是法压壶能够提升一下鉴赏咖啡的水平.
在尝试了两次之后发现还是挺不错的,也是开始进行变量控制来尝试自己最喜欢的配比跟步骤吧:
博客分类 空闲的时候重新回来看了看博客的分类着实有些杂乱,后面打算写文章也不知道往哪里分比较好就重构了一下自己博客的分类方式,现在也算是比较满意了吧(最起码新写博客的时候不再为了这个分类头疼了).
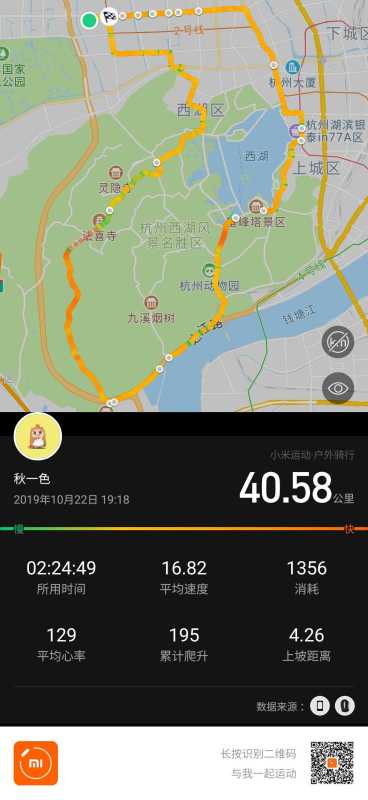
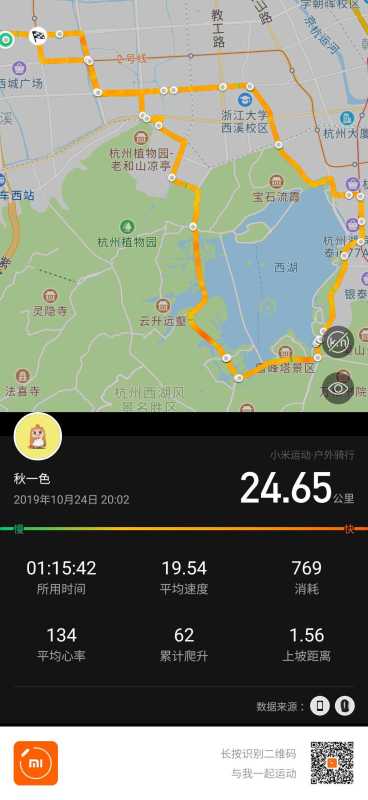
骑行 鉴于不断增加的体重和国庆回家期间被家里人的不断叮嘱,还是觉得要增加一下运动量的嘛,正好拿到了人才补助的钱就想着整了一辆自行车,一来可以代步二来附近也没什么可以跑步的场地正好尝试一下骑行的快乐⑧.
若饭 这是之前看小众软件的时候被推荐了一波,结合上面打算运动一下减减肥的理念,也就尝试了一下新手套餐发现液体的饮料还是比较能接受的(喝上去感觉和豆奶很像),就整了一罐粉末来当晚饭.个人感觉还是可以接受的,饱腹感也还可以.就先体验一下,说不定也会有回购和体验的测评.
总结 周报周报,可能对我来说更像是多了一个文字输出的渠道吧,毕竟网络社交渠道基本都已经是断绝了,有一个输出口也不见得是一件坏事.
当然有时候似乎很坚信自己现在清晰的知道自己究竟想要什么,在做什么,但是有时在陌生的边缘徘徊的时候又觉得自己似乎几年来还是一个dio样子又不免让人觉得蕉躁.
当然,多想多看,多写写日志吧.
吾尝终日而思矣 不如须臾之所学也