给localhost套上tls的翅膀
在tls成为互联网冲浪不可或缺的今天,给localhost加上tls证书也并不是什么很潮流的事情了,换句话说:所有环境尽可能保持一致才能更好的开发和debug。而且吾辈在以前也遭遇过本地http的坑:chrome会因为没有tls证书而给请求加载限速,导致nodejs的dev环境启动巨慢。。在各大浏览器厂商都歧视http的今天,我们不得不给我们最经常访问的域名加上tls的魔法了。
mkcert
作为web.dev推荐的证书生成工具当然好处不少,(谁说对了就给他)
mkcert(和类似工具)具备下列几种优势:
- mkcert 专门用于创建与浏览器认为有效相兼容的证书。它会保持更新,来满足需求和最佳实践。因此您无需运行具备复杂配置或参数的 mkcert 命令,就可以生成正确的证书!
- mkcert 是跨平台的工具。团队中的任何人都可以使用。
使用
1
2
| mkcert -cert-file certs/local-cert.pem -key-file certs/local-key.pem \
"*.dev.localhost"
|
Traefik + Portainer
traefik是什么
生成一段不少于300字的对 traefik proxy 项目的功能介绍和与Nginx的对比
1
2
3
4
5
| Traefik Proxy是一款高效的、现代化的反向代理服务器,它被设计成可自动化配置的,它可以检测新的服务和容器的出现,并自动地加入到服务集群中。Traefik Proxy支持多种后端服务,比如docker、Kubernetes、Mesos、Swarm等,并可以自动地为它们生成路由规则。它还支持多种协议,包括HTTP、TCP和UDP,并且支持SSL、WebSocket、DNS等特性。Traefik Proxy具有极高的可扩展性,它可以横向扩展,并且可以自动地配置和平衡集群。
与Nginx相比,Traefik Proxy具有更多的优势。首先,Traefik Proxy是自动化的,我们无需手工编写和修改配置文件,它能自动地检测和配置新的容器和服务,并自动地生成路由规则。这样,使用Traefik Proxy,我们可以轻松地管理大规模的服务集群。其次,Traefik Proxy是可编程的,并且有着可扩展的API。使用Traefik Proxy,我们可以自定义路由规则,创建并定制HTTP中间件,以及为我们自己的特殊需求来开发插件。再次,Traefik Proxy支持多种后端服务,比如docker、Kubernetes、Mesos等,这使得我们可以更好地管理多个容器和服务。此外,Traefik Proxy具有较小的内存占用和快速的性能,这保证了它具有卓越的响应时间。
在总体比较中,Traefik Proxy是一个更好的选择。它可以自动地配置和管理服务集群,支持多种后端服务和协议,并具有Out-of-the-box的可用性,可编程性和可扩展性。与此相比,Nginx可能需要更多的手动配置和调整,并且不是那么自适应。因此,如果我们需要管理服务集群,那么Traefik Proxy是更好的选择。
|
portainer是什么
生成一段不少于300字的对 portainer 项目的功能介绍
1
2
3
4
5
6
7
8
9
| Portainer是一款基于Web的容器管理平台,该平台提供了简单、易用的UI界面,帮助用户管理单个或多个Docker环境。Portainer是一个开源项目,用户可以自由下载、使用、修改、扩展和分享该项目。
Portainer的功能非常强大,它提供了几乎所有常用的Docker管理命令,包括容器、镜像、卷、网络、服务、堆栈等。用户可以对容器进行管理,包括创建、删除、启动和停止等。用户也可以对镜像进行管理,包括搜索、下载、创建和删除等。此外,用户可以管理卷,创建和删除网络,部署和管理服务,以及管理堆栈。
Portainer提供了易用的界面,使用户能够轻松地监视和管理Docker容器和服务。用户可以轻松地访问、管理和修改Docker配置文件。Portainer还提供了多个用户支持,用户可以创建多个用户并为不同的用户配置不同的权限。因此,用户可以轻松地管理不同级别的用户。
Portainer的另一个重要特点是可扩展性。它是一个开源项目,拥有活跃的社区,新功能和改进不断涌现。用户可以根据其需求,通过开发和使用插件来扩展Portainer的功能,以满足其特定的Docker管理要求。
总之,Portainer是一款功能强大、易用和可扩展的Docker管理平台。其提供了全面而又可视化的Docker管理工具,帮助用户监视和管理单个或多个Docker环境。同时,它是一个开源项目,具有灵活的设计和可扩展性,可以满足不同的Docker管理需求。
|
traefik配置
首先我们需要给traefik配置mkcert生成的tls文件路径,这一步暂时没有找到如何在label直接进行配置,后面如果发现如何免除额外的yml文件会进行更新。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
http:
routers:
traefik:
rule: "Host(`traefik.dev.localhost`)"
service: "api@internal"
tls:
domains:
- main: "dev.localhost"
sans:
- "*.dev.localhost"
tls:
certificates:
- certFile: "/etc/certs/local-cert.pem"
keyFile: "/etc/certs/local-key.pem"
|
然后我们就可以创建一个docker-compose.yml文件了,这部分骨架可以从portainer文档中找到:Deploying Portainer behind Traefik Proxy。因为我们是在本地使用mkcert创建的证书,所以就需要忽略certificatesresolvers部分的配置。经过改动之后的配置文件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
version: "3.3"
services:
traefik:
container_name: traefik
image: "traefik:latest"
command:
- "--api.dashboard=true"
- --entrypoints.web.address=:80
- --entrypoints.websecure.address=:443
- --providers.docker
- --providers.file.directory=/etc/traefik/dynamic_conf
- --log.level=DEBUG
ports:
- "80:80"
- "443:443"
networks:
- traefik-public
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro"
- ./certs:/etc/certs:ro
- ./dynamic_config.yaml:/etc/traefik/dynamic_conf/conf.yml:ro
labels:
- "traefik.http.routers.http-catchall.rule=hostregexp(`{host:.+}`)"
- "traefik.http.routers.http-catchall.entrypoints=web"
- "traefik.http.routers.http-catchall.middlewares=redirect-to-https"
- "traefik.http.middlewares.redirect-to-https.redirectscheme.scheme=https"
portainer:
image: portainer/portainer-ce:latest
command: -H unix:///var/run/docker.sock
restart: always
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- portainer_data:/data
networks:
- traefik-public
labels:
- "traefik.enable=true"
- "traefik.http.routers.frontend.rule=Host(`portainer.dev.localhost`)"
- "traefik.http.routers.frontend.entrypoints=websecure"
- "traefik.http.routers.frontend.tls=true"
- "traefik.http.services.frontend.loadbalancer.server.port=9000"
- "traefik.http.routers.frontend.service=frontend"
- "traefik.http.routers.edge.rule=Host(`edge.dev.localhost`)"
- "traefik.http.routers.edge.entrypoints=websecure"
- "traefik.http.services.edge.loadbalancer.server.port=8000"
- "traefik.http.routers.edge.service=edge"
volumes:
portainer_data:
networks:
traefik-public:
external: true
|
最终我们的本地文件如下:

首先创建网络:docker network create traefik-public
使用docker-compose up便可以启动服务,访问https://traefik.dev.localhost/dashboard/便可以看到traefik自带的dashboard。
访问https://portainer.dev.localhost便可以进入portainer。
通过Portainer创建和管理docker服务
我们使用一个简单的项目来进行测试,这里我选了memos:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| version: "3.0"
services:
memos:
image: neosmemo/memos:latest
container_name: memos
volumes:
- memos:/var/opt/memos
networks:
- traefik-public
labels:
- "traefik.enable=true"
- "traefik.http.routers.memos.rule=Host(`memos.dev.localhost`)"
- "traefik.http.routers.memos.entrypoints=websecure"
- "traefik.http.routers.memos.tls=true"
- "traefik.http.services.memos.loadbalancer.server.port=5230"
- "traefik.http.routers.memos.service=memos"
volumes:
memos:
networks:
traefik-public:
external: true
|
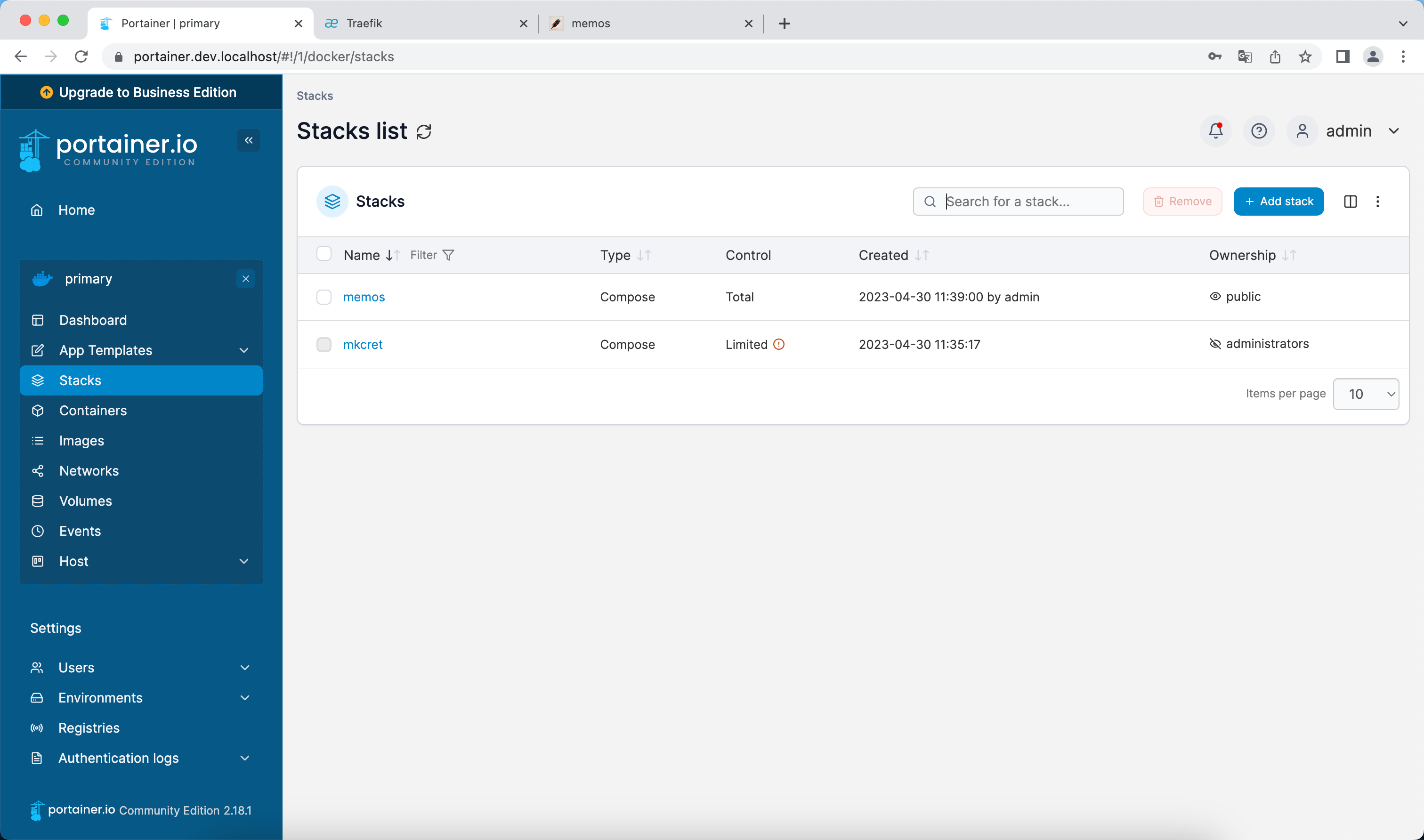
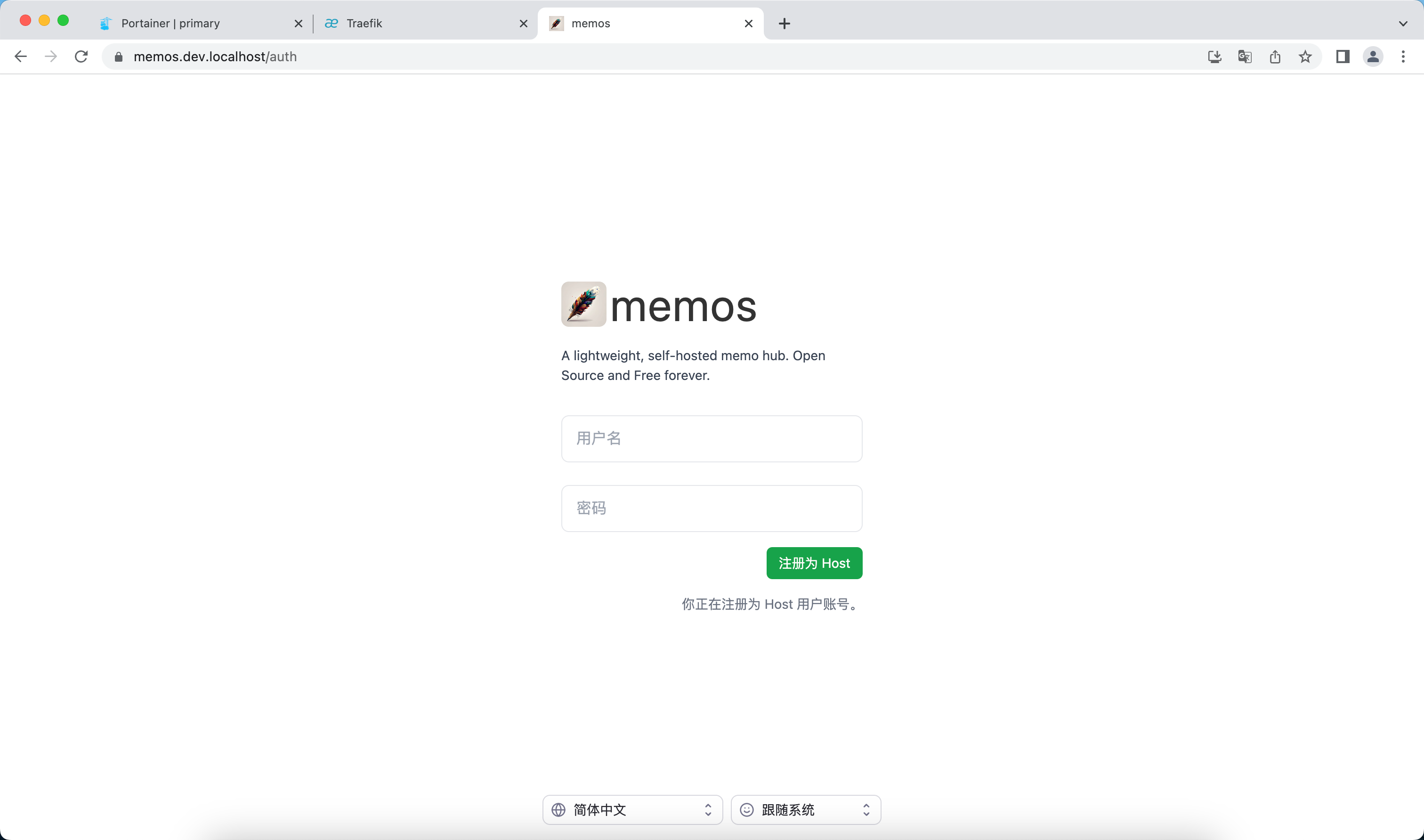
成功访问:
参考文章
大致流程参考:
How to handle https with docker-compose and mkcert for local development
意识到需要配置network提供互联性:
Application monitoring with Traefik, Prometheus, Grafana, and Docker Compose for beginners
把两个文件优化成只有一个动态文件:
Setting Up Traefik 2 with Local SSL Certificate