第一部分: 什么是日志
什么是日志
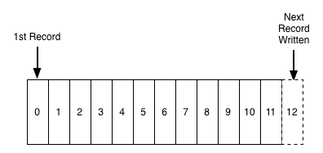
- 新记录被添加到尾部
- 读取顺序从左至右
- 每个记录都会被赋予一个唯一的,顺序的编号
- 日志记录的顺序定义了一个“时间”的概念
- 日志的编号可以理解为一个时间戳(相对时间)
- 日志和文件或者(数据)表没有区别
- 日志的目的是:用于记录发生了什么和什么时候发生的 ==> 分布式系统所关心的核心问题
- 日志的类型:
- 应用日志:非结构化的错误信息或者应用跟踪信息
- 数据日志:为程序访问设计 这里讨论的类型
数据库中的日志
作为一种ACID模型的实现细节,日志的作用:
- 保证数据结构的同步
- 崩溃恢复时的数据索引
- 使用日志记录将要被修改的记录的信息
- 日志记录在数据上发生了什么
作为数据库之间的同步的方法 (MySQL主从同步通过日志实现)
分布式系统中的日志
分布式系统的设计核心问题: 如何根据事件发生的顺序在多台机器上更新对应的数据并保持同步
也就是: 使得多台机器都对接收的相同的分布式日志进行相同的操作
日志解决了两个问题:
- 有序的变化 (事件顺序)
- 分布式的数据
状态机复制原理:
如果两个确定性的进程以相同的状态开始并且以相同的顺序获得相同的输入,则产生相同的输出并且结束在相同的状态(状态机的性质)
- 确定性意味着处理过程过程与时间无关
- 状态指进程留在机器上的任何数据
- 确定性的处理过程就是确定性的(deterministic processing is deterministic)
日志的目的是排除了输入流中的全部的不确定性,确保处理相同数据的每个节点状态都保持同步
这种方法的好处在于索引日志的时间戳可以作为每个节点状态的唯一ID来表达每个节点的状态
分布式系统中两种复制和处理数据的方法:
- 主-主模型:每个节点都到日志读取操作复制到本地进行操作和状态的保持,例如每个节点读取 ”+1“,”*2“操作到本地进行计算然后保存结果
- 主-备模型:选举一个主节点进行数据的操作,把操作的结果记录到日志里供其他节点读取,例如主节点进行”+1“,”*2“的操作,把操作的结果”1“,”3“,”6“记录到日志给其他节点读取
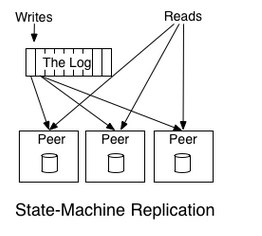
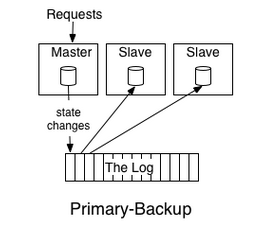
这也揭示了为什么记录的顺序是数据一致性的关键:操作的顺序不同就会导致完全不一样的结果(运算顺序不同结果也会不同)
一些分布式一致性协议
- Paxos
- ZAB
- RAFT
- Viewstamped Replication
日志和表的二象性
把日志类比成银行账户的交易记录的话
- 表: 当前账户的状态
- 日志: 表的所有状态的备份
所以可以看到日志所能表达的信息量是比表多很多的,但是相对于的存储的成本也高很多
第二部分: 数据集成
数据集成指:一个组织的所有数据对这个组织所有的服务和系统可用
马斯洛的层次需求理论
- 收集所有相关的数据
- 放到适当的处理环境中
- 建议可靠完整的数据流
- 有了数据和处理过程:
- 关注更好的数据建模
- 更好的可视化,报表,处理算法,数据预测
两个难题
- 事件数据流水线
- 记录发生了什么而不是产生的结果
- 数据量比传统数据量级大很多,处理更加困难
- 专用数据系统的爆发: 集成更加困难
日志结构的数据流
- 提取所有组织的数据并放入用于实时订阅的日志中心
- 每个数据源都可以建模成日志
- 日志的概念为每次更改提供了逻辑时钟
- 日志可以充当缓冲区,是数据的产生和消耗可以异步进行
- 目标系统只需要知道日志而不需要知道数据源系统的任何信息
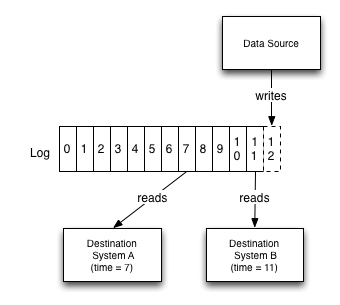
在LinkedIn
大量的数据专用系统:
- Search
- Social Graph
- Voldemort (key-value store)
- Espresso (document store)
- OLAP query engine
- …
原先的数据管道架构:
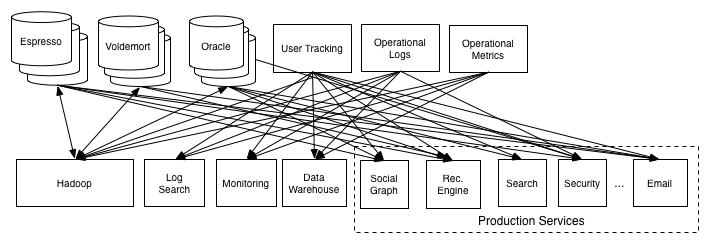
直接使用管道对接数据源的问题:
任何时候任何管道都可能出问题,在坏数据上进行操作只会产生更多坏数据
在实践中意识到的几件事:
- 虽然很混乱,但是建立的管道是有价值的
- 需要对数据管道更深入的支持才能对数据进行可靠的加载
- 数据覆盖率仍然很低
需要的架构: 一个数据源只连接一个单一的管道 ==> kafka
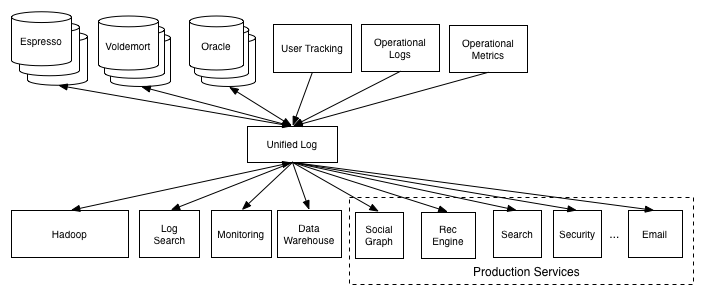
ETL和数据仓库的关系
数据仓库
- 一个干净,集成的数据仓库,其结构支持分析
- 定期从数据源提取数据
- 将其拼凑成可以理解的形式
- 加载到一个中心数据仓库
- 不能对数据进行实时处理
ETL
- 提取和清理数据的过程
- 将数据重组成用于查询的结构
数据仓库团队的经典问题
- 通常不了解数据仓库中的数据如何使用
- 创建难以提取或者很难获取的数据
- 很难转换成可用的形式
一个更好的形式
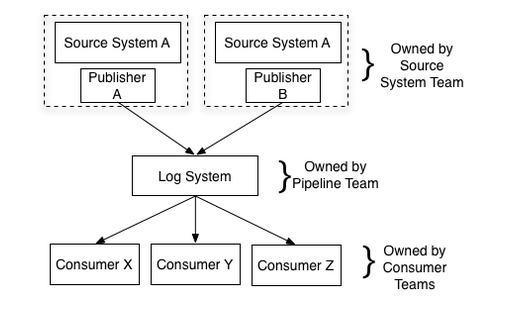
- 一个中心管道
- 定义良好的用于添加数据的API
- 组织的可扩展性
- 可以提供完整数据集的搜索功能
- 亚秒级的数据流监控
- 进行特定的清理或转换的位置
- 由数据生产者完成后添加到中心日志(最好的方法, 可以保证中心日志系统数据的规范性)
- 在日志中心进行实时转换(会产生转换日志)
- 由加载数据的系统进行处理
- 在添加数据时保留原有的数据格式,需要的特定操作在处理原始数据时进行
- 只有针对目标系统的聚合操作才应该加到加载过程中
日志文件和事件
优势: 支持解耦的事件驱动的系统
构建可伸缩的日志
- 日志分片
- 通过批量读写优化吞吐量
- 避免无用的数据拷贝
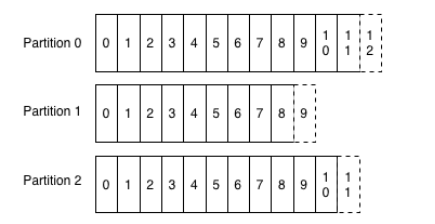
- 每个分片的日志是有序的,但是分片之间没有全局的次序
- 由写入者决定消息发送到特定的日志分片
- 每个分片通过可配置数字指定数据复制的复本个数,每个复本都有一个分片日志完全一致的一份拷贝
- 对于顺序读写可以方便地优化
第三部分:日志与实时流处理
- 日志是流处理的核心
- 流处理是连续数据处理的基础架构
- 计算模型是通用的
- 具有低延迟产生结果的能力
- 数据的收集方法是真正的驱动力:
- 分批收集的数据自然进行分批处理
- 连续收集数据时自然进行连续的处理
- 连续处理可以平滑的处理资源并且降低延迟
流处理的另一个观点
- 处理数据时引入了时间概念
- 不需要数据的静态快照
- 可以控制输出的频率
- 不需要等待数据集收集结束再进行处理
- 是批处理的一种泛化
其实只有很少的公司拥有实时数据流,因为缺少实时的数据收集
在金融领域实时数据流已经成为标准并且流处理已经成为了瓶颈
流处理覆盖了实时响应服务和离线批处理架构之间的差距
日志解决的最大问题是使得多订阅者可以获得实时的数据输入
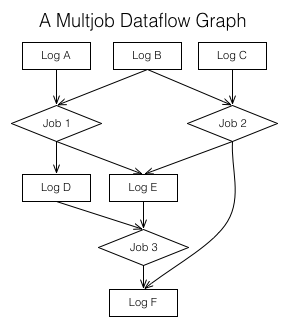
数据流图
- 扩展了早期对数据集成中数据订阅的想法
- 根据订阅的数据进行计算得出新的订阅数据
- 可以封装处理的复杂性
- 可以把所有对组织中数据获取,转换和数据流处理操作视为一系列的日志以及对其写入过程进行处理的结合
- 日志在其中的作用:
- 使得每个数据集可以有多个订阅者并且保证有序
- 提供了对数据处理的缓冲
有状态的实时处理
需要在流处理的某个大小的时间窗口内进行更复杂的计数、聚合和关联操作
如何支持类似”表”的东西并将其与处理过程分开:
- 把流转换为同一位置的表
- 把状态保持在本地表或者索引中
- 允许崩溃重启恢复
- 处理过程的状态也保持为日志
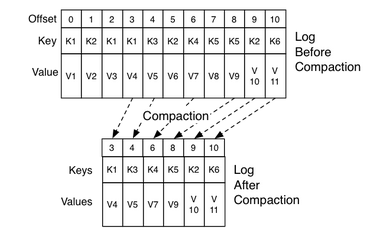
日志合并
-
两种数据清理的形式:
- 事件数据,
Kafka支持仅维护一个窗口的数据 - 键值存储数据,使用压缩技术,通过重放技术来重建源系统的状态
- 事件数据,
-
删除过时的记录但是保证日志包含了源系统的完整备份
-
不再重现原系统曾经的所有状态,只保留最新的状态
第四部分:系统构建
- 分拆系统
- 把整个组织系统和数据流视为单个分布式数据库
- 面向系统的查询只是特定的索引
- 流处理是一种完善的触发器和视图的实现机制
- 将每个系统的许多小实例合并为几个大集群
- 对于现有系统过多的复杂度,三个可能的进化方向
日志在分布式系统中的地位
日志能做什么:
- 处理数据的一致性问题
- 提供节点之间的数据复制
- 提供”提交”语义(在保证写入不丢失时才确认写入)
- 提供系统的外部数据订阅
- 提供从失败副本恢复丢失数据或者引导新副本的能力
- 处理节点之间的数据重平衡
这也是一个分布式系统所需要做的
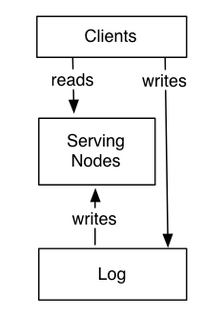
如何工作
分为两个逻辑部分:
- 日志: 按顺序捕获状态变化
- 服务层
- 服务节点存储查询所需索引
- 服务节点订阅日志
- 按照日志存储顺序尽快写入本地索引
- 接收到请求时
- 比较请求需要的时间戳和自己的索引位置
- 延迟请求直到索引位置超过请求时间戳,保证数据正确性
分布式系统中比较复杂的事
- 处理故障节点
- 在节点之间移动分区
处理方法:
- 使日志保留一个数据窗口和分区数据存储的快照结合
- 日志保留完整的数据副本并进行垃圾回收
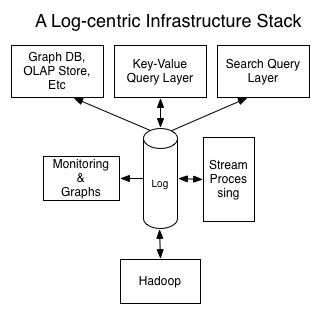
以日志为核心的分布式系统
- 把查询相关的因素和系统的可用性与一致性解耦
- 日志是一种特别有效的存储机制
- 日志系统只执行线性的读取和写入
- 系统的强度取决于日志的使用方式