14.6 InnoDB在磁盘上的结构(InnoDB On-Disk Structures)
14.6.1 表(Tables)
14.6.1.1 创建InnoDB表
使用CREATE TABLE语句来创建一个InnoDB表
CREATE TABLE t1 (a INT, b CHAR (20), PRIMARY KEY (a)) ENGINE=InnoDB;如果InnoDB是默认的存储引擎的话你不需要特定指定ENGINE=InnoDB,可以使用下面语句检查默认的存储引擎
mysql> SELECT @@default_storage_engine;
+--------------------------+
| @@default_storage_engine |
+--------------------------+
| InnoDB |
+--------------------------+如果你计划使用mysqldump或Replication在一个默认存储引擎不是InnoDB的服务器上重用CREATE TABLE语句时仍旧可以使用ENGINE=InnoDB子句.
InnoDB表和它的索引被创建在系统表空间(system tablespace),单表单文件(file-per-table)表空间或通用表空间( general tablespace)中.当innodb_file_per_table启用的时候,默认情况下,InnoDB表会被隐式的创建在一个单独的单表单文件表空间中.相反的,当innodb_file_per_table禁用的时候,InnoDB表会被隐式的创建在系统表空间中.使用CREATE TABLE ... TABLESPACE可以在通用表空间中创建表.
当你创建InnoDB表的时候,MySQL会创建一个**.frm文件在MySQL数据文件的数据库目录下.对于创建在单表单文件表空间中的表,MySQL也会默认创建一个.ibd表空间文件在数据库目录下.在InnoDB的系统表空间中创建的表被创建在一个已经存在的ibdata文件中,该文件保存在MySQL的数据目录下.在通用表空间中创建的表被创建在已存在的.ibd**文件中.通用表空间文件可以被创建在MySQL数据目录内或之外.
在内部,InnoDB在InnoDB数据字典里为每一张表增加一个目录.这个目录包括了数据库名.例如,在test数据库里创建t1表,数据目录的名字就是test/t1.这意味着你可以在不同的数据库里创建一个同名的表并且在InnoDB里不会冲突.
InnoDB表和.frm文件
InnoDB表默认的行格式(row format)由innodb_default_row_format来定义,默认值为DYNAMIC.Dynamic和Compressed行格式允许你使用InnoDB特性例如表压缩和有效的长列值的页外存储.要使用行格式,innodb_file_per_table必须要启用并且innodb_file_format必须设置为Barracuda.
SET GLOBAL innodb_file_per_table=1;
SET GLOBAL innodb_file_format=barracuda;
CREATE TABLE t3 (a INT, b CHAR (20), PRIMARY KEY (a)) ROW_FORMAT=DYNAMIC;
CREATE TABLE t4 (a INT, b CHAR (20), PRIMARY KEY (a)) ROW_FORMAT=COMPRESSED;另外,你可以使用CREATE TABLE ... TABLESPACE语句在通用表空间中创建InnoDB表.通用表空间支持全部行格式.
CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1 ROW_FORMAT=DYNAMIC;CREATE TABLE ... TABLESPACE也可以被用来在系统表空间里创建一个行格式为Dynamic以及Compact或Redundant的InnoDB表.
CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE = innodb_system ROW_FORMAT=DYNAMIC;InnoDB表和主键(Primary Keys)
总是为InnoDB表指定主键,指定下面的一列或多列:
- 被最重要的查询引用
- 永远不为空
- 永远不会有重复值
- 在插入之后很少改变
例如,在一张包含人员信息的表里,你不会在(firstname, lastname)上创建主键,因为不止一个人可以有相同的名字,一些人last name是空的,一些人会改名.在这么多的约束下,通常不会有很明显的列来做主键,所以你创建了一个新的列叫数字ID作为主键或者主键的一部分.你可以声明一个自增(auto-increment)列使得在插入行的时候自增.
# The value of ID can act like a pointer between related items in different tables.
CREATE TABLE t5 (id INT AUTO_INCREMENT, b CHAR (20), PRIMARY KEY (id));
# The primary key can consist of more than one column. Any autoinc column must come first.
CREATE TABLE t6 (id INT AUTO_INCREMENT, a INT, b CHAR (20), PRIMARY KEY (id,a));虽然表可以在没有定义主键的情况下工作,但是主键涉及到性能的许多方面并且是任何大型或者经常使用的表的关键的设计方面.建议在CREATE TABLE语句中就指定主键.如果你创建表,加载数据后使用ALTER TABLE来添加一个主键会比创建表时定义主键慢得多.
查看InnoDB表属性
mysql> SHOW TABLE STATUS FROM test LIKE 't%' \G;
*************************** 1. row ***************************
Name: t1
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 0
Avg_row_length: 0
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2015-03-16 15:13:31
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)InnoDB表的属性也可以使用INFORMATION_SCHEMA表来查看:
mysql> SELECT * FROM INFORMATION_SCHEMA.INNODB_SYS_TABLES WHERE NAME='test/t1' \G
*************************** 1. row ***************************
TABLE_ID: 45
NAME: test/t1
FLAG: 1
N_COLS: 5
SPACE: 35
FILE_FORMAT: Antelope
ROW_FORMAT: Compact
ZIP_PAGE_SIZE: 0
SPACE_TYPE: Single
1 row in set (0.00 sec)14.6.1.2 移动或复制InnoDB表
这个部分介绍移动或者拷贝部分或全部InnoDB表到不同的服务器或实例的技术.例如,你也许想把整个MySQL实例移动到一个更大,更快的服务器上去;你也许想克隆整个MySQL实例到一个新的主从同步的从服务器上去;你也许要拷贝个别的表到另一个实例上用来开发或者测试应用,或者到一个数据仓库用来产生报表.
在Windows上,InnoDB总是使用小写来存储数据库和表名.用二进制格式移动数据库从Unix到Windows或者从Windows到Unix,使用小写名称来创建所有数据库和表名.一个简便的方法是在创建数据库和表名之前在你的my.cnf或者my.ini文件的[mysqld]部分添加下面的行.
[mysqld]
lower_case_table_names=1移动或者复制InnoDB表的技术包括:
- 可传输表空间(Transportable Tablespaces)
- Mysql企业备份(MySQL Enterprise Backup)
- 复制数据文件(冷备份方法)(MySQL Enterprise Backup)
- 导入和导出(mysqldump)(Export and Import )
可传输表空间
可传输表空间特性使用FLUSH TABLES ... FOR EXPORT来准备要从一个服务器实例拷贝到另一个的服务器的表.为了能够使用这个特性,InnoDB表的innodb_file_per_table必须为ON,使得每一张InnoDB表都有它自己的表空间.
Mysql企业备份
MySQl企业备份使你可以在一个正在运行的MySQL数据库上以最小的损害产生快照.当MySQL企业备份在拷贝表的时候,读和写操作可以继续.此外,MySQL企业备份可以创建一个压缩过的备份文件并且可以只备份表的一部分.结合MySQL的binlog,你可以进行时间点恢复.MySQL企业备份包括在MySQL企业订阅中.
复制数据文件
你可以简单地移动一个InnoDB数据库通过拷贝冷备份(Cold Backups)相关的所有文件.
InnoDB数据和日志文件在所有平台上是二进制兼容的,有相同的浮点数格式.如果浮点数格式不同但是在你的表中没有使用FLOAT和DOUBLE数据类型的话,过程是一样的:拷贝相关文件.
当你移动或者拷贝每个表的.ibd文件时,源系统和目标系统的数据库文件夹名必须是相同的.存储在InnoDB共享表空间中的表的定义中包括了数据库名.存储在表空间文件中的事务ID和日志序列号也和数据库中的不同.
要移动.ibd文件和相关的表到另一个数据库,使用RENAME TABLE语句.
RENAME TABLE db1.tbl_name TO db2.tbl_name;如果你有.ibd文件的”干净”的备份,你可以将其还原到安装的MySQL上,操作如下:
- 在你拷贝了.ibd文件之后这个表不能被删除或者截断,因为这样会改变存储在表空间中的表ID.
- 使用
ALTER TABLE语句删除当前的.ibd文件:
ALTER TABLE tbl_name DISCARD TABLESPACE;- 复制备份的.ibd文件到正确的目录下
- 使用下面的
ALTER TABLE语句来告诉InnoDB使用新的.ibd文件
ALTER TABLE tbl_name IMPORT TABLESPACE;在这里,一个”干净”的.ibd备份文件要满足下面的要求:
- .ibd文件中没有未被提交的事务修改
- .ibd文件中不能有没有被合并的insert缓存
- 清除操作(purge)已经移除了.ibd文件中的全部被标记删除的索引.
- mysqld已经把所有被修改的页面都从缓冲池刷到了.ibd文件中.
你可以使用下面的方法来制作一个”干净”的.ibd文件:
- 停止mysqld服务的全部活动和提交所有的事务.
- 等到
SHOW ENGINE INNODB STATUS显示数据库没有活动的事务并且InnoDB的主线程状态是waiting for server activity之后,你可以复制一个.ibd文件.
另一个制作干净的.ibd文件的办法是使用MySQL企业备份:
- 使用MySQL企业备份备份InnoDB的安装
- 在备份上启动第二个mysqld服务来清理.ibd文件
导入和导出
你可以使用mysqldump转存你的表然后在另一台机器上导入转存的文件.使用这种方式,格式是否一样或你的表包含浮点数据都没关系.
一个提高性能的方法是在导入数据的时候关闭自动提交(autocommit),如果表空间有足够的空间用于导入事务生产的大回滚段(rollback segment).在导入表或者表的一部分后手动执行提交.
14.6.1.3 把表从MyISAM转换到InnoDB
如果你想要以更高的可靠性和更好的拓展性把MyISAM表转换成InnoDB表的话,在进行转换之前查看下面的引导:
调整MyISAM和InnoDB的内存使用
当你在转换MyISAM表的时候,降低key_buffer_size配置的值来释放不需要的缓存结果.提高 innodb_buffer_pool_size配置的值,它扮演了类似为InnoDB表分配缓存内存的角色.InnoDB的缓冲池同时缓存表数据和索引数据用来加速查询的查找速度和保存查询结果在内存里以重用.
在繁忙的服务器上,关闭查询缓存后运行性能测试.InnoDB缓存池提供了类似的好处,所以查询缓存也许会占用不必要的内存.
处理过长或过短的事务
因为MyISAM表不支持事务,你也许需要把更多注意力放在自动提交(autocommit)配置选项以及COMMIT和ROLLBACK语句上.这些关键字对于允许多会话对InnoDB表的并发读写很重要,对于写入繁重的工作来说提供了坚实的可拓展性优势.
当一个事务打开的时候,系统会保存一个事务开始时的数据快照,如果在事务保持运行的时候系统进行了百万行杂散的插入,更新和删除操作的话会造成大量的开销.因此,请注意避免运行时间过长的事务:
- 如果你使用一个mysql会话来进行交互性实验,在结束的时候总是进行
COMMIT或ROLLBACK.关闭交互式会话而不是长时间保持开启,来避免意外地长时间保持一个事务在开启状态. - 确保你应用中的任何错误处理也会使用
ROLLBACK回滚未完成的更改或COMMIT提交已完成的更改. ROLLBACK是一个相对开销比较大的操作,因为INSERT,UPDATE和DELETE操作在COMMIT操作之前都被写入到了InnoDB表中,因为大部分的改变都会被成功的提交并且很少被回滚.在实验大量数据时,避免改变大量的行然后回滚这些变动.- 使用
INSERT语句加载大量数据时,定期使用COMMIT提交结果来避免长达几小时的事务.在典型的数据仓库加载操作中,如果出了问题,使用TRUNCATE TABLE来重新开始而不是使用ROLLBACK.
前面的提示可以减少长时间事务中内存和磁盘的浪费.当事务比它应当的大小更小时,问题更多出在I/O上.对于每一个COMMIT,MySQL都会确保每一个变更都安全地记录到磁盘上了,这会涉及到一些I/O.
- 对于InnoDB表的多数操作,你应该使用autocommit=0的设置.从效率的角度来看,这避免了在你提交大量连续的
INSERT,UPDATE或DELETE时候的不必要的I/O.从安全的角度来看,这允许你使用ROLLBACK语句来恢复丢失或者乱码的数据,在你在mysql命令行犯了错误或者你的应用进行错误处理的时候. - 当运行一系列的查询来生成报告或进行分析统计的时候autocommit=1对于InnoDB表来说是合适的.在这种情况下,没有与
COMMIT和ROLLBACK相关的I/O,InnoDB可以自动地优化只读的工作负载. - 如果你进行了一系列的相关更改,最后用一个
COMMIT来完成全部的更改.例如,如果你把相关的信息插入到几个表中,使用一个COMMIT进行所有的更改.或者你运行许多连续的INSERT语句然后在所有数据被加载之后使用一个COMMIT;如果你在运行百万行的INSERT语句,也许通过使用COMMIT每次提交一万或十万条记录来拆散这个大事务可以使得事务不会变得太大. - 请记住,甚至一个
SELECT语句也会打开一个事务,所以在mysql交互式会话中运行一些报告或者调试的查询之后,执行一个COMMIT或者关闭mysql会话.
处理死锁(Deadlocks)
你也许会在MySQL错误日志看到一些警告信息提到死锁或者在SHOW ENGINE INNODB STATUS的输出中.尽管名字听起来很可怕,但是对于InnoDB表来说这个问题一点都不严重并且通常不需要任何的纠正动作.当两个事务开始修改多张表的时,它们以不同的顺序访问表,可以到达一种状态:每一个事务都在等在其他的事务并且都不能继续下去.当死锁检测(deadlock detection)开启的时候(默认开启),MySQL会马上检测到这种情况并且取消(rollback)“较小”的事务,允许另一个继续下去.如果死锁检测被innodb_deadlock_detect选项配置禁用的话,InnoDB会根据innodb_lock_wait_timeout设置回滚发生死锁的事务.
无论哪种方式,你的应用都需要一个错误处理逻辑来重启由于死锁被强制取消的事务.当你提交了和之前相同的sql语句,原来提交的就不会被接受了.如果另一个事务已经完成那么你可以继续,另一个事务还在处理中那么就要等到它结束.
如果死锁警告持续发生,你也许需要重审你的应用代码,以一致的方式编排SQL语句或者缩短事务.你可以开启innodb_print_all_deadlocks配置进行测试用以在MySQL错误日志中看到全部的死锁警告,要比查看SHOW ENGINE INNODB STATUS的输出只能看到最后一个警告好得多.
规划存储布局
为了InnoDB表获得最好的性能,你可以调整和存储布局相关的一些参数.
当你转换一个大的,经常使用并且保存重要数据的MyISAM表的时候,调查并考虑innodb_file_per_table,innodb_file_format和innodb_page_size配置选项,以及CREATE TABLE语句中的ROW FORMAT和KEY BLOCK SIZE选项.
在你的初始实验期间,最重要的设置是innodb_file_per_table.当这个设置启用的时候(MySQL5.6.6之后是默认值),新的InnoDB表会被隐式的创建在单表单文件(file-per-table)表空间里.和InnoDB系统表空间相比,单表单文件表空间允许操作系统在表被删除和截断(truncate)后回收磁盘空间.单表单文件的表空间也支持 Barracuda文件格式以及相关的特性,例如:表压缩,可变长的长列的页外效率存储和大索引前缀.
你也可以把InnoDB表存储在共用的通用表空间里.通用表空间支持Barracuda文件格式并且包含多个表.
转换现有表
使用下面的sql:
ALTER TABLE table_name ENGINE=InnoDB;注意
不要把在mysql库中的MySQL系统表从MyISAM转换到InnoDB.这是一项不受支持的操作.
克隆一个表的结构
你可以通过克隆一个MyISAM表来创建InnoDB表而不是使用ALTER TABLE进行转换,在转换之前要在新旧表的两边进行测试.
用相同的列和索引的定义来创建一个空的InnoDB表.使用SHOW CREATE TABLE table_name\G来查看建表时使用的完整的语句.把ENGINE部分改成ENGINE=INNODB.
传输现有数据
把大量的数据传输到如上面所示的空的InnoDB表中,使用INSERT INTO innodb_table SELECT * FROM myisam_table ORDER BY primary_key_columns来插入行.
你也可以在数据插入结束后为InnoDB表创建索引.在以前,创建一个新的二级索引对InnoDB来说是一个比较慢的操作,但是现在你可以在数据加载结束之后创建索引而索引创建步骤的开销相对较小.
如果你对二级键有UNIQUE约束,你可以在导入操作期间暂时性的关闭唯一性检查来加入表的导入:
SET unique_checks=0;
... import operation ...
SET unique_checks=1;对于大表来说可以节省磁盘I/O,因为InnoDB可以使用变更缓冲区(change buffer)对二级索引进行批量的写入.要确保数据不包含重复键.唯一性检查( unique_checks)允许但不要求存储引擎忽略重复键.
为了更好地控制插入过程,您可以用下面的代码块插入大型表格:
INSERT INTO newtable SELECT * FROM oldtable
WHERE yourkey > something AND yourkey <= somethingelse;在插入了所有数据后,你可以重命名表.
在转换大表期间,增加InnoDB缓冲池的大小来减少磁盘I/O,最大设置物理内存的80%.你也可以增加InnoDB日志文件的大小.
存储要求
如果你打算在转换过程中创建多个InnoDB表数据的临时拷贝,建议你在单表单文件表空间中创建表以便在删除表的时候回收磁盘空间.当innodb_file_per_table配置选项启用的时候(默认启用),新创建的表会被隐式的创建到每个表的表空间文件中去.
无论你是直接转换到InnoDB表还是创建InnoDB的克隆表,确保在此过程中有足够的磁盘空间来容纳旧表和新表.InnoDB表比MyISAM表需要更多的磁盘空间.如果ALTER TABLE操作空间不足的话会开启回滚,如果受到磁盘限制的话,可能需要几小时.对于插入,InnoDB使用插入缓存将二级索引批量合并到索引中.这能节省大量磁盘I/O.对于回滚没有使用这样的机制,(所以)回滚可能比插入时间长30倍.
在回滚失控的情况下,如果你的数据库里没有有价值的数据,建议杀死数据库进程而不是等到数百万的磁盘I/O完成.
给每个表定义一个主键
PRIMARY KEY子句是MySQL查询和表和索引的使用情况的一个重要影响因子.主键唯一标识表中的行.表中的每一行都一定有一个主键并且没有两行会有相同的主键.
下面是主键的准则和详细的解释:
- 对每一个表声明一个主键.通常,它是在查找单行时在WHERE子句中引用的最重要的列.
- 在
CREATE TABLE建表语句时指定主键要比建表之后使用ALTER TABLE指定要好. - 仔细选择列的数据类型.首选数字列而不是字符或者字符串.
- 考虑使用自增列如果表中没有其他稳定的,不重复的,非空的数组列使用的话.
- 如果对主键的值是否会发生变化有疑问的话,自增的列也是一个好选择.更改主键列的值是一个代价高昂的操作,可能涉及重新排列表格中的数据和每一个二级索引.
考虑将主键添加到还没有使用的表中.基于项目最大的大小来使用最小的数字类型.这可以使得列之间更加紧凑,这可以为大表节省大量空间.如果表具有二级索引的话,节省的空间是成倍增加的,因为主键值在每个二级索引中重复.除了减少磁盘上的数据大小,一个小的索引也使得更多的数据进入缓冲池,加速各种操作和提高了并发.
如果表已经在一些大的列上有了索引,例如VARCHAR,考虑增加一个新的自增的无符号列并且把主键切换到上面,即使查询中没有使用这列.这种改变可以在二级索引中节省大量空间.你可以将以前的主键列指定为UNIQUE NOT NULL来确保其和主键有相同的约束来防止这些列出现重复和空值.
如果你在多个表中传递信息,通常对每个表使用相同的列作为主键.例如,一个人员数据库可能有几张表,每一张都用员工号来做主键.销售数据库可能有一些表用顾客编号来做主键并且另一些表以订单ID做主键.因为使用主键的查找速度非常快,你可以对每张表构建有效的连接查询.
如果你不使用PRIMARY KEY子句,Mysql会为你创建一个不可见的.它是一个6位的值可能比你要的还长,这会浪费空间而且你不能在查询中引用它(因为是不可见的).
应用程序性能注意事项
InnoDB的可靠性和可拓展性特性使得其相对于MyISAM表来说需要更多的磁盘空间.你可以稍微更改列和索引定义,为了更好地利用空间,在处理结果集的时候减少I/O和内存消耗,以及使用索引查找的时候更好的查询优化计划来提高效率.
如果你使用数字ID作为主键,使用这个值和其他表中相关的值进行交叉引用,特别是join查询.例如,不是接受一个国家名称作为输入进行查询和使用相同的名称进行查询,而是执行一次查找确定国家ID,然后执行在其他表中查询相关信息的查询.不是将客户或目录编号作为数字串,而是使用几个字节转化为数字ID来进行存储和查询.一个4位的无符号整数列可以索引超过40亿件物品.
了解InnoDB表关联的文件
InnoDB文件比MyISAM文件需要更多的关注和计划.
- 你不能删除InnoDB系统表空间中的ibdata文件
- 移动和拷贝InnoDB表到不同的服务器参考14.6.1.2 移动和复制InnoDB表
14.6.1.4 InnoDB中的自增处理
InnoDB提供了一种可配置的锁机制可以显著提高向具有自增(AUTO_INCREMENT)列的表添加数据时的可扩展性和性能.为了在InnoDB表中使用自增机制,一个自增列必须被定义为索引的一部分,这样就可以在表上执行等效的被索引的SELECT MAX(ai_col)查找以获得最大列值.通常,这是通过在某些表中使列成为第一列来实现的.
这个部分描述了自增(AUTO_INCREMENT)锁的行为模式,不同设置模式的含义和InnoDB如何初始化自增计数器.
InnoDB自增锁模式(InnoDB AUTO_INCREMENT Lock Modes)
这个部分描述了自增锁模式被用来生成自增值时候的行为以及每种锁模式如何影响复制.自增锁模式的配置参数是innodb_autoinc_lock_mode
下面是innodb_autoinc_lock_mode配置的描述:
-
INSERT-like子句在表中生成新行的所有语句,包括
INSERT,INSERT ... SELECT,REPLACE,REPLACE ... SELECT和LOAD DATA.包括简单插入(simple-inserts),批量插入(bulk-inserts)和混合模式插入(mixed-mode). -
简单插入(simple-inserts)
语句中可以预先确定要插入的行数.这包括没有嵌套子查询的单行和多行的插入以及替换语句但是不包括
INSERT ... ON DUPLICATE KEY UPDATE. -
批量插入(bulk-inserts)
语句中预知要插入的行数.包括
INSERT ... SELECT,REPLACE ... SELECT和LOAD DATA语句,但不是普通的INSERT.InnoDB在处理每一行的时候都为自增列生成一个新值. -
混合模式插入(mixed-mode)
这些是简单插入语句但是指定了其中的一些自增列的值.例如:
INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d');另一种混合模式插入是
INSERT ... ON DUPLICATE KEY UPDATE,最坏的情况下是在INSERT后面加一个UPDATE,在更新阶段可能会或不会使用自增列的已分配的值.
innodb_autoinc_lock_mode有3种可能的设置参数.分别是0,1,2代表传统的(traditional),连续的(consecutive)和交叉的(interleaved)锁模式.
-
innodb_autoinc_lock_mode = 0(传统锁模式)
传统锁模式提供了和MySQL5.1引入
innodb_autoinc_lock_mode配置之前相同的行为.提供传统锁模式选项是为了向后兼容,性能测试以及解决”混合模式插入”问题,因为在语义上可能存在差异.在这个锁模式下,所有”INSERT-like”语句都会获得一个特殊的表级
AUTO-INC锁,用来插入有自增列的表.此锁通常保持在插入语句的末尾(而不是事务的末尾)来确保对于给定的一系列插入语句能够以可预测和可重复的顺序为其分配自增值,并且确保对于任意给定的语句自增值都是连续的.在基于语句复制的情况下,在slave上执行sql语句的时候会使用与master在自增列上相同的值.执行多个插入语句的结果是确定的并且slave上产生的数据和master是相同的.如果多个插入语句生成的自增值是交错的,那么两个并发的INSERT操作产生的结果是不确定的并且使用基于语句的复制传递到slave的数据是不可靠的.
为了清楚起见,使用下面的示例:
CREATE TABLE t1 ( c1 INT(11) NOT NULL AUTO_INCREMENT, c2 VARCHAR(10) DEFAULT NULL, PRIMARY KEY (c1) ) ENGINE=InnoDB;假设有2个事务在运行,每一个插入的行都有一个自增的列.一个事务使用
INSERT ... SELECT语句插入1000行,另一个使用简单的INSERT插入操作.Tx1: INSERT INTO t1 (c2) SELECT 1000 rows from another table ... Tx2: INSERT INTO t1 (c2) VALUES ('xxx');InnoDB无法预知Tx1事务到底SELECT了多少行进行插入,所以随着语句的执行每次分配一个自增的值.由于使用保持在语句末尾的表级锁,在t1表上同时只能有一个插入语句执行,并且不同的插入语句生成的自增的数值也是无关的.所以Tx1事务中生成的数值是自增的而Tx2中的自增数值比Tx1大还是小取决于两个事务哪个先执行.
只要以相同的顺序执行binlog中的sql语句,结果就和Tx1和Tx2第一次执行时一样.因此,保持到语句结束的表级锁使得使用自动增量的插入语句可以安全地用于基于语句的复制.但是,当多个事务同时执行插入语句的时候,表级锁限制了并发性和可伸缩性.
在上面的例子里,如果没有表级锁,Tx2事务的插入语句中自增列的值就取决于语句执行的时间.如果Tx2的插入语句在Tx1插入语句正在执行的时候执行,这两个插入语句产生的自增列的值就变得不确定了,而且每次运行都可能不同.
在”连续锁”模式下,InnoDB可以避免对能够预先知道插入行数的”简单插入”语句使用表级的
AUTO-INC锁,并且仍旧保持执行顺序的确定性和基于语句复制的安全性.如果你不使用binlog重播sql语句(的形式)作为恢复或复制的一部分,交错锁模式(interleaved lock mode)可用于消除所有表级锁
AUTO-INC的使用来实现更高的并发和性能,以允许语句产生的自增数的差距和由于并发产生自增数字交错为代价. -
innodb_autoinc_lock_mode = 1 (连续锁模式)
这是默认的锁模式.在这种模式下,批量插入使用了特殊的
AUTO-INC表级锁并且保持到语句结束.适用于所有INSERT ... SELECT,REPLACE ... SELECT和LOAD DATA语句.同时只能有一个语句持有AUTO-INC锁.如果批量插入的原表和目标表不同,AUTO-INC锁会在从原表第一行获取了共享锁之后对目标表加锁.如果原表和目标表相同的话,AUTO-INC锁会在获取了共享锁之后对所有被SELECT的行加锁.“简单插入”(预先知道行数的插入)通过在互斥锁(一个轻量锁)的控制下获得所需的自增值的数量来避免表级的
AUTO-INC锁,互斥锁只会在分配的过程中持有,而不是直到语句执行结束之后.除非有另一个事务持有AUTO-INC锁,否则不会使用AUTO-INC锁.如果另一个事务持有AUTO-INC锁,简单插入会等待AUTO-INC释放,就像批量插入一样.这种锁模式确保在不知道给定的INSERT语句要插入的行数的情况下,所有
INSERT-like的语句分配的自增值都是连续的,并且基于语句的复制是安全的.简而言之,这种锁模式显著的提高了可伸缩性同时可以安全的使用基于语句的复制.此外,和传统锁模式一样给任意语句的自增值都是连续的.对于任何有自动增量的语句,与传统模式相比语义上没有变化,但是有一个重要的例外.
这个例外是对于”混合模式”插入,因为用户提供了其中的一部分自增列的值,InnoDB申请的自增列的数量会比需要的量更多,但是因为自增列的值生成都是连续的,所以后执行的插入语句的值会高于之前的,(前一个语句)多出来的数值就丢失了.
-
innodb_autoinc_lock_mode = 2 (交错锁模式)
在这种锁模式下,任何插入相关的语句都不会使用
AUTO-INC锁,多个语句可能同时执行.这是最快和最具扩展性的锁模式,但是使用基于从binlog回放语句的复制或恢复的时候,这是不安全的.在这种模式下,自增的值保证是唯一的并且在所有执行的插入语句中单调递增,但是并发的插入会导致生成的自增值会产生交错,所以对于一个插入语句来说里面的自增值可能是不连续的.
如果唯一执行的语句是在插入之前知道要插入的行数的简单插入语句那么单个语句生成的自增值之间是没有间隙的,除了”混合模式插入”.然而,当执行批量插入的时候,任何给定的语句中的自增数值可能存在间隙.
InnoDB 自增锁模式的使用含义(InnoDB AUTO_INCREMENT Lock Mode Usage Implications)
-
使用自增(auto-increment)进行复制
如果你使用基于语句的复制,在master和slave上把
innodb_autoinc_lock_mode设置成相同的值(0或1).如果你设置”innodb_autoinc_lock_mode = 2”或者主从不使用相同的锁模式则不能保证主从上的自增键的值是相同的.如果你使用基于行或者混合格式的复制,任何一个模式都是安全的因为基于行的复制对于sql的执行顺序不敏感(混合格式就是对不安全的基于语句的复制使用基于行的复制).
-
丢失自增值和序列间隙(sequence gaps)
在所有的锁模式中(0,1和2),如果生成自增值的事务回滚的话,这些自增值就会丢失.一旦为自增列生成了值,无论是插入的语句没有完成还是包含的事务是否回滚这些生成的值都不能回滚.这些丢失的值不会被重用.因此,表中的自增列可能会存在间隙(sequence gaps).
-
给自增的列指定NULL或0
在所有的锁模式下,用户在INSERT语句中给自增的列指定NULL或0,InnoDB都会视为这些行没有被指定值然后为其生成一个新值.
-
给自增的列指定一个负值
在所有锁模式中,如果你给自增列指定一个负值那么就不会给其定义自增的机制.
-
如果自增列的值大于对应列数据类型的最大值
在所有锁模式下,如果值大于指定整数类型可以存储的最大值就不会给其定义自动增加机制.
-
批量插入中的自增值的间隙
在
innodb_autoinc_lock_mode设置为0(传统的)和1(连续的)时,任何给定的语句生成的自增值都是连续的,没有间隙,因为AUTO-INC锁会保持到语句结束并且同时只能执行一个语句.在
innodb_autoinc_lock_mode设置为2(交错)时,生成批量插入的自增值的时候可能会产生间隙,因为只有这个时候会并行执行多个INSERT-like语句.
对于锁模式1和2,在连续的语句之间可能会存在间隙,因为对于批量插入不可能知道每个语句确切需要的数量并且可能会高估. -
混合模式插入指定的自增值
考虑一个混合模式插入:在一个简单插入中指定一些(但不是全部)自增值.这样的语句在模式0,1,2中表现不同.例如,假定t1表有一个自增列c1,并且最近生成的自增值是100.
mysql> CREATE TABLE t1 ( -> c1 INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY, -> c2 CHAR(1) -> ) ENGINE = INNODB;现在,考虑下面的混合模式插入的语句:
mysql> INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d');innodb_autoinc_lock_mode为0会产生下面4行:mysql> SELECT c1, c2 FROM t1 ORDER BY c2; +-----+------+ | c1 | c2 | +-----+------+ | 1 | a | | 101 | b | | 5 | c | | 102 | d | +-----+------+下一个可用的自增值是103因为每次分配一个自增值而不是在处理语句时一次性分配.无论是否同时执行了插入语句,结果都是一样的.
innodb_autoinc_lock_mode为1会产生下面4行:mysql> SELECT c1, c2 FROM t1 ORDER BY c2; +-----+------+ | c1 | c2 | +-----+------+ | 1 | a | | 101 | b | | 5 | c | | 102 | d | +-----+------+然而这种情况下下一个可用的自增值是105而不是103,因为在处理语句时分配了4个值而只使用了2个.无论是否同时执行了插入语句,结果都是一样的.
innodb_autoinc_lock_mode为1会产生下面4行:mysql> SELECT c1, c2 FROM t1 ORDER BY c2; +-----+------+ | c1 | c2 | +-----+------+ | 1 | a | | x | b | | 5 | c | | y | d | +-----+------+x和y的值是唯一的并且比之前生成的值都大.但是x和y的具体值取决于并发执行语句时生成的自增值.
最后,考虑下面的语句在最近生成的自增值为100时执行:
mysql> INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (101,'c'), (NULL,'d');在任何一个
innodb_autoinc_lock_mode设置下都会生成一个重复键错误 error 23000(Can’t write; duplicate key in table)因为101是分配给(NULL, ‘b’)这一行的所以插入(101, ‘c’)会失败. -
在一系列插入语句中间修改自增列的值
在所有锁模式下,在一系列插入语句中间修改自增列的值都会导致重复条目(Duplicate entry)错误.例如,如果你执行了一个
UPDATE操作更改自增列的值为大于当前自增列最大值的话,后续的未指定自增列值的操作可能会遇到重复条目(Duplicate entry)错误.下面是一个演示:mysql> CREATE TABLE t1 ( -> c1 INT NOT NULL AUTO_INCREMENT, -> PRIMARY KEY (c1) -> ) ENGINE = InnoDB; mysql> INSERT INTO t1 VALUES(0), (0), (3); mysql> SELECT c1 FROM t1; +----+ | c1 | +----+ | 1 | | 2 | | 3 | +----+ mysql> UPDATE t1 SET c1 = 4 WHERE c1 = 1; mysql> SELECT c1 FROM t1; +----+ | c1 | +----+ | 2 | | 3 | | 4 | +----+ mysql> INSERT INTO t1 VALUES(0); ERROR 1062 (23000): Duplicate entry '4' for key 'PRIMARY'
InnoDB自增计数器初始化
这个部分介绍InnoDB怎么初始化自增计数器.
如果你为InnoDB表指定一个自增的列,InnoDB数据字典的表句柄会包含一个计数器叫做自增计数器(auto-increment counter)用来给列分配新值.这个计数器只存储在主内存里而不是磁盘上.
为了在服务器重启后重新初始化自增计数器,InnoDB会在包含自增列的表中进行第一次插入时执行和下面等价的语句:
SELECT MAX(ai_col) FROM table_name FOR UPDATE;InnoDB会递增这个检索到的值然后将其分配给列和表的自增计数器.默认情况下,自增的值是1.这个默认值可以由auto_increment_increment配置覆盖.
如果表是空的,InnoDB使用1.这个默认值可以由auto_increment_offset覆盖.
如果SHOW TABLE STATUS在自增计数器初始化之前检查该表,InnoDB会初始化(自增计数器)但不会递增该值.这个值会被存储用于用户的下一次插入.这个初始化使用常规独占锁在表上进行读取并且锁会持续到事务结束.InnoDB遵循相同的过程来初始化新建表的自增计数器.
在自增计数器被初始化之后,如果你没有给自增列显式地指定值的话,InnoDB会递增计数器然后给列分配新值.如果插入显式指定自增列值的行并且值比计数器当前值更大的话,计数器会被设置为这个指定的列值.
InnoDB会在服务器运行的时候使用内存中的自增值计数器.当服务器停止并重启时,InnoDB会初始化每个表的计数器用于表的第一次插入.
服务器重启还会取消CREATE TABLE和ALTER TABLE语句中AUTO_INCREMENT = N对表的影响,你可以使用InnoDB表来设置初始计数器的值或更改当前计数器的值.
14.6.1.5 InnoDB和外键约束
外键定义(Foreign Key Definitions)
InnoDB表的外键定义受到以下约束:
- InnoDB允许外键引用任何索引或索引组.但是在引用的表中必须有一个被列为first列的列被引用且是以相同的顺序.
- InnoDB当前不支持用户定义分区的表的外键.这意味着没有用户分区的InnoDB表可以包含外键引用或被外键引用的列.
- InnoDB允许外键约束引用一个非唯一键.这是InnoDB对标准SQL的一个拓展.
引用操作(Referential Actions)
InnoDB表的外键引用操作受到下面限制:
- 虽然MySQL服务器允许
SET DEFAULT但是InnoDB视其为无效.在CREATE TABLE和ALTER TABLE语句中使用这个子句都不会被InnoDB表允许. - 如果在父表中有几行数据有相同的引用键值,InnoDB在外键检查中会起作用就像父表中其他有相同键值的行不存在一样.例如,如果你定义了一个
RESTRICT类型约束,并且一个子行有多个父行,InnoDB不允许删除父行中的任何一个. - InnoDB基于索引中对应的外键约束记录通过深度优先算法进行级联操作.
- 如果
ON UPDATE CASCADE或ON UPDATE SET NULL递归更新它在级联期间更新的同一个表,行为就像RESTRICT.这也就意味着你不能在ON UPDATE CASCADE或ON UPDATE SET NULL中使用自我指涉.这是为了防止级联更新导致无限循环.另一方面ON DELETE SET NULL这样的自我指涉是可能的,这个就像ON DELETE CASCADE一样.指涉操作深度不能操作15级. - 就像MySQL通常做的,一个SQL语句插入,删除或更新多行,InnoDB逐行检查唯一(UNIQUE)和外键(FOREIGN KEY)约束.执行外键检查时,InnoDB会在需要查看的子记录和父记录上设置共享行级锁.InnoDB会立即检查外键约束;检查不会延迟到事务提交.根据SQL标准,默认行为应该是延迟检查.也就是在处理完整个SQL语句后才会检查约束.在InnoDB实现延迟约束检查之前,有些事是不可能的,例如删除使用外键引用自身的记录.
生成列和虚拟索引的外键限制
- 对存储的生成列的外键约束不能使用
ON UPDATE CASCADE,ON DELETE SET NULL,ON UPDATE SET NULL,ON DELETE SET DEFAULT, 或ON UPDATE SET DEFAULT. - 外键约束不能引用虚拟生成列.
- 在5.7.16之前,外键约束不能引用定义在虚拟生成列上的二级索引.
- 在MySQL5.7.13及之前,InnoDB不允许在索引虚拟生成列的基列上使用级联引用操作定义外键约束.在MySQL 5.7.14解除了这个限制.
- 在MySQL 5.7.13及更早版本中,InnoDB不允许在显式包含在虚拟索引中的非虚拟外键列上定义级联引用操作.在MySQL 5.7.14中解除了这个限制.
14.6.1.6 InnoDB表的限制
最大值和最小值(Maximums and Minimums)
-
一张表最多包含1017列(MySQl5.6.9之前是1000列).虚拟生成列也包含在这个限制里.
-
一张表最多包含64个二级索引.
-
如果
innodb_large_prefix启用(默认值),对InnoDB使用DYNAMIC或COMPRESSED行格式的表的索引前缀的限制是3072字节.如果innodb_large_prefix禁用,对表的任何行格式索引前缀的限制都是767字节.innodb_large_prefix已弃用,在以后的版本中将删除.innodb_large_prefix在MySQL5.5中引入用来禁用大前缀索引,为了和早期的InnoDB版本兼容.对于使用REDUNDANT或COMPACT行格式的InnoDB表,索引前缀的限制是767字节.例如,你可能在
TEXT或VARCHAR列超过255个字符的时候遇到这个列前缀索引限制,假定是一个utf8mb3字符集,每个字符最大是3个字节.尝试使用超出限制的索引键前缀长度会返回错误.要避免复制配置中的这类错误,避免在master上开启
innodb_large_prefix配置如果在slave上不生效的话.适用于索引前缀键的限制也适用于全列索引键.
-
如果在启动MySQL实例时通过修改
innodb_page_size将InnoDB页大小减少到8kb或4kb,根据16kb页面3072字节的限制,索引键的最大长度也会按比例降低.8kb最大索引键长度是1536字节,4kb最大索引键长度是768字节. -
多列索引最多允许16列,超过限制会返回下面错误:
ERROR 1070 (42000): Too many key parts specified; max 16 parts allowed -
除了可变长列(VARBINARY,VARCHAR,BLOB和TEXT)之外最大行长度略小于4KB,8KB,16KB和32KB的页面大小.例如,
innodb_page_size默认的最大行长度是16KB大约8000字节.对64KB大小的InnoDB也来说,最大行长度大概是16000字节.LONGBLOB和LONGTEXT列必须小于4GB,并且包括BLOB和TEXT列的总长度必须小于4GB. 如果一行的长度小于半页,所有行都存储在页内.如果超过半页,可变长列会被选择存储到页外部直到行适合半页. -
虽然InnoDB内部支持行大小超过65535字节,但是MySQL本身对所有列组合添加65535字节的行大小限制.
mysql> CREATE TABLE t (a VARCHAR(8000), b VARCHAR(10000), -> c VARCHAR(10000), d VARCHAR(10000), e VARCHAR(10000), -> f VARCHAR(10000), g VARCHAR(10000)) ENGINE=InnoDB; ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBs -
在一些旧的操作系统中,文件必须小于2GB.这不是InnoDB自身的限制,但是如果你需要一个大表空间配置其使用几个小的数据文件而不是一个大的数据文件.
-
InnoDB日志文件总大小可以达到512GB.
-
最小的表空间大小比10MB稍大.最大表空间大小取决于InnoDB页面大小.
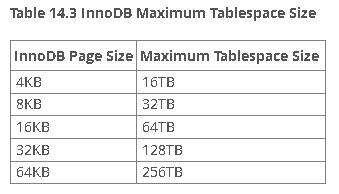
最大表空间大小也就是表的最大大小.
-
在Windows32位系统中表空间文件不能超过4GB(Bug #80149).
-
表空间文件的路径包括文件名,不能超过Windows中最大路径(MAX_PATH)的限制.Windows10中MAX_PATH限制为260个字符.从Windows10 1607版本开始MAX_PATH限制将从常见的Win32文件和目录函数中删除,但是你必须启用新行为.
-
InnoDB默认页面大小是16KB.你可以在创建MySQL实例的时候通过配置
innodb_page_size来增加或减少页面大小.Barracuda文件格式中的ROW_FORMAT=COMPRESSED假定页面大小最多16KB并且使用14位指针.
支持32KB和64KB页面大小,但是 ROW_FORMAT=COMPRESSED不支持不支持超过16KB的页面大小.对于32KB和64KB页面大小最大记录大小是16KB.
innodb_page_size=32k范围为2MB,innodb_page_size=32k范围是4MB.使用特定页面大小的Mysql实例不能使用来自不同页面大小实例的数据文件和日志文件.
InnoDB表的限制
-
ANALYZE TABLE通过在每个索引树上执行随机下潜(random dives)来确定索引基数和更新相应的索引基数.因为只是估计,重复运行ANALYZE TABLE可能产生不同的数值.这使得在InnoDB表上ANALYZE TABLE很快但不是100%准确,因为不会考虑所有行.可以通过开启
innodb_stats_persistent选项使得ANALYZE TABLE更精确更稳定.启用该设置后,在对索引列数据进行重要更改后运行ANALYZE TABLE非常重要,因为统计数据不会定期重新计算(比如服务器重启).如果启用了持久统计信息设置,你可以通过修改
innodb_stats_persistent_sample_pages系统变量来改变随机下潜(random dives)的次数.如果禁用持久统计信息设置,修改innodb_stats_transient_sample_pages来代替.MySQL在join优化中使用索引基数估计.如果join操作没有被正确优化,尝试使用
ANALYZE TABLE.在少数情况下,ANALYZE TABLE不能为特定的表生成足够好的值,你可以对查询使用FORCE INDEX来强制使用特定索引或通过设置max_seeks_for_key系统变量来确保MySQL优先考虑通过表扫描进行索引查找. -
如果语句或事务正在表上运行,一个
ANALYZE TABLE运行在相同的表上紧接着第二个ANALYZE TABLE操作,第二个ANALYZE TABLE操作会被阻止直到语句或事务完成.这个问题出现的原因是ANALYZE TABLE结束运行后会使得当前加载表被定义为已过时.新语句或事务(包括第二个ANALYZE TABLE语句)必须将新表加载到表缓存中,在完成当前运行的语句或事务并清除表的已过时定义之前(加载新表)这种情况是不会发生的.加载多个并发表定义是不支持的. -
SHOW TABLE STATUS不能给出InnoDB表的确切信息除了表格保留的物理尺寸.行计数只是SQL优化中使用的粗略估计. -
InnoDB不保留表中的内部行数,因为并发事务可能同时”看到”不同数量的行.因此,
SELECT COUNT(*)语句只计算当前事务可见的行数. -
在Windows上,InnoDB始终在内部以小写的形式存储数据库和表名.要以二进制格式将数据库从Unix移动到Windows或从Windows移动到Unix,使用小写名创建所有的数据库和表.
-
必须将自增列
ai_col定义为索引的一部分,以便在表上执行和SEELCT MAX(ai_col)等效的索引查找时获取最大值.通常这是通过是列成为某些表索引的第一列来实现的. -
InnoDB在初始化表上先前指定的自增列时在自增列相关的索引末尾设置独占锁.
innodb_autoinc_lock_mode=0时,InnoDB使用特殊的AUTO-INC表级锁模式,在此模式下获取锁并在访问自动增量计数器时保持到当前SQL语句的末尾.在保持AUTO-INC表锁时,其他客户端无法插入表中.使用innodb_autoinc_lock_mode = 1的”批量插入”时也会出现相同的行为.表级锁AUTO-INC不与innodb_autoinc_lock_mode = 2一起使用 -
当你重新启动MySQL服务器时,InnoDB可能会重复使用为自增列生成但从未存储过的旧值(也就是在回滚的旧事务期间生成的值).
-
当自增整数列用完值时,后续INSERT操作将返回重复键错误(duplicate-key error).这是正常的MySQL行为.
-
DELETE FROM tbl_name不会重新生成表,而是逐个删除所有行. -
级联外键操作不会激活触发器.
-
您不能创建一个列名与内部InnoDB列的名称匹配的表(包括DB_ROW_ID, DB_TRX_ID, DB_ROLL_PTR 和 DB_MIX_ID).此限制适用于把名称任何字母小写的情况.
mysql> CREATE TABLE t1 (c1 INT, db_row_id INT) ENGINE=INNODB; ERROR 1166 (42000): Incorrect column name 'db_row_id'锁和事务(Locking and Transactions)
如果innodb_table_locks=1(默认值)LOCK TABLES会在每个表上获取2个锁.除了MySQL层面上的表锁也需要InnoDB的表锁.MySQL 4.1.2之前版本不需要InnoDB表锁;通过设置innodb_table_locks=0来使用这种旧的行为.如果没有获取InnoDB表锁,即使表的某些记录被其他事务锁定,LOCK TABLES也会完成.
在MySQL 5.7中,innodb_table_locks=0对于使用 LOCK TABLES ... WRITE显式锁定表没有任何影响.它对隐式的LOCK TABLES ... WRITE(例如通过触发器)或LOCK TABLES ... READ有效.
- 事务提交或中止时,将释放事务持有的所有InnoDB锁.因此,在
autocommit = 1模式下在InnoDB表上调用LOCK TABLES没有多大意义,因为获取的InnoDB表锁将立即释放. - 你无法在事务中锁定其他表,因为
LOCK TABLES隐式执行COMMIT和UNLOCK TABLES.