优点
- 解决了特征稀疏的问题,能在非常非常稀疏数据的情况下进行预估
- 解决了特征组合的问题
- FM是一个通用的模型,适用于大部分的场景
- 训练速度快,线性复杂度
开始
先附上视频的地址:机器学习算法讲堂(3):FM算法 Factorization Machine
我们首先从线性回归解法的角度来看一个特征组合的问题,如果现在数据涉及到训练集中的两个特征,那么LR就要写成:
可以看到在这个方程中,随着特征选取的数量变多,特征组合之后的复杂度是特征数量个N相乘,这是在训练过程中不能接受的,并且线性回归的方法只能在不为0的情况下进行训练,对于稀疏的数据来说训练是不充分的.而FM解决的就是LR复杂度过高和对稀疏数据训练不充分的缺点.
FM的思路就是将W分解为,这也就是FM名字的由来,等于是因式分解W.接下来是FM的推导的过程:
首先引入辅助变量
已知特征矩阵W为:
V矩阵为:
且有结论:当k足够大时,对于任意对称正定实矩阵,均存在实矩阵使得
这样一来,我们只要找到一个就可以解决这个问题了,而分解成的优势在于有效的降低了算法的复杂度,下面是对FM算法的求解:
根据上面的分解,可以将FM公式写为:
这里主要需要求解的就是最后一项:
我们可以看到公式化简到最后,复杂度就只和求和符号上的k,n相关了,所以复杂度可以简单的记为O(nk),但是这已经比之前的线性回归的解法复杂度低了很多了,这可以视为是线性的复杂度.
下面看一下FM的梯度的计算,我们对分别求偏导可以写为:
最后一个公式可以化为:
我们可以看到这个梯度计算的公式中,计算复杂度也只和n相关也就是说:复杂度是O(n)!相比于简单的LR动不动的N方的复杂度来说,FM的复杂度可以说是相当的低了.
拓展
这里就只是先列举一下FM的一些拓展使用:
下面就放几个图片吧(这次是自己截图放的图床)
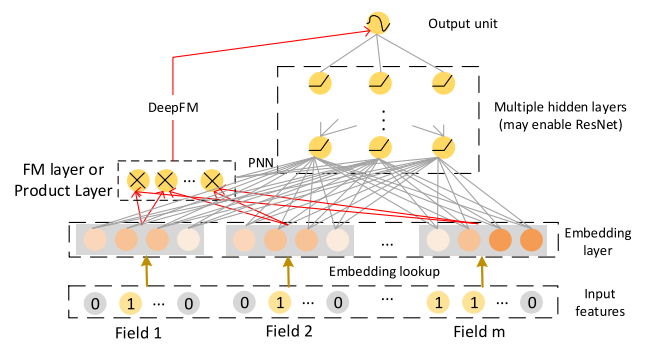
DeepFM:
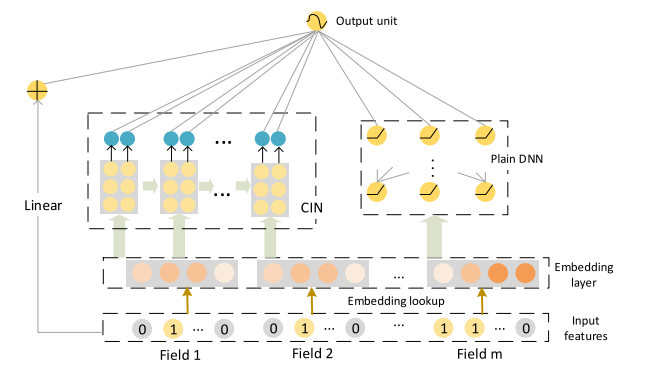
xDeepFM:
贴一下论文的地址:
Factorization Machines
xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems